
Autonomous vehicles have come a long way. On controlled highways and structured urban environments, modern autonomous vehicle systems navigate familiar conditions with remarkable precision across increasingly complex deployment environments. But place one in front of a collapsed traffic barrier at midnight, an unmarked detour through a construction zone, or a cyclist carrying an oversized load, and the cracks appear fast.
This is the reality of the long tail: the sprawling universe of rare, unpredictable scenarios that standard training pipelines cannot anticipate at scale. Bridging that gap requires more than collecting more data. It requires knowing which data matters. That is exactly what edge case triage in autonomous systems addresses, and why it has become one of the most important disciplines in the race toward safe, reliable autonomy.
What Is Edge Case Triage in Autonomous Systems?
Edge case triage is the process of identifying, categorizing, and prioritizing high-value data points from within the vast long-tail scenarios that fall outside routine operating conditions. Think of it as the bridge between raw data collection and meaningful model improvement, the step that separates teams building genuinely safer autonomous vehicles from those simply accumulating sensor footage.
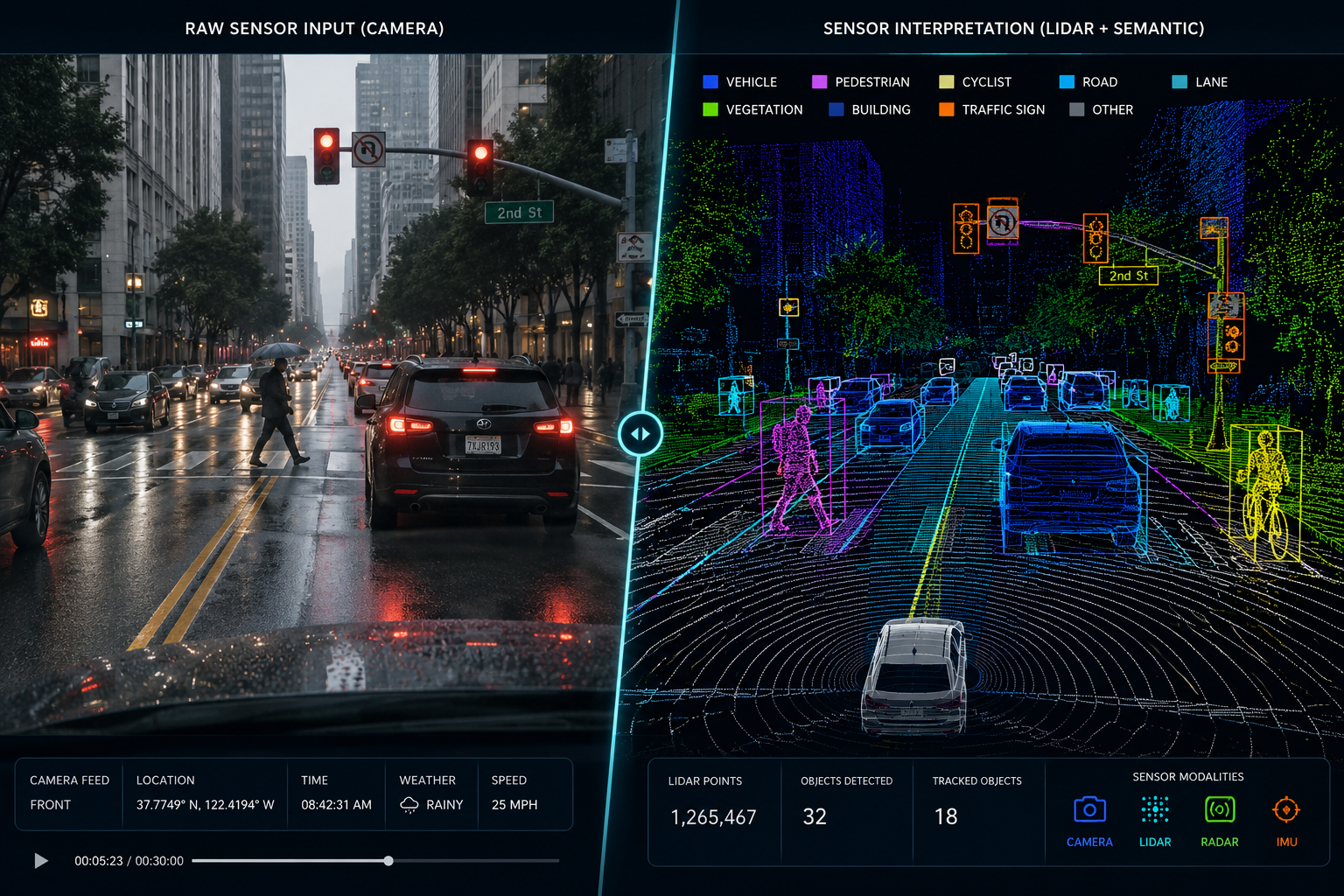
The word “triage” is deliberate. Not every rare event deserves equal attention annotation budgets, engineering cycles, and compute are all finite. So instead of treating every data point equally, triage asks the questions that matter: Where are the biggest safety gaps? Which scenarios, once labeled and retrained on, will actually move the needle? This is the shift from “more data is better” to smart data; where quality and relevance matter more than volume.
Why Triage Is Non-Negotiable for Model Improvement
Data Efficiency at Scale
AV fleets generate staggering volumes of sensor data every single day. The vast majority of it is redundant clear roads, predictable traffic, unremarkable conditions the model already handles confidently. Treating all of it as equally valuable is one of the most expensive mistakes an AV team can make.
Edge case triage solves this by directing annotation resources precisely where the model is weakest. Each targeted labeling cycle corrects a specific blind spot. Over time, this compounds: fixing one edge case reduces uncertainty around adjacent scenarios, accelerating model improvement without scaling headcount linearly with data volume. The impact is measurable by focusing resources on high-value data exceptions through this method, a leading Robotaxi company achieved a 250% improvement in annotation efficiency.
Bottlenecks Are Specific and Fixable
When an autonomous vehicle underperforms, the failure is almost never diffuse. It is anchored to specific, often counterintuitive conditions. Consider two examples from iMerit’s work with autonomous systems clients: in the “Shoulderless Road” scenario, models trained on standard road geometry failed to identify boundaries when traditional shoulders were absent, iMerit’s team intervened to teach the model to detect road edges directly from available visual cues. In a separate “Clear or Cloudy” case, models relying solely on sky color to interpret weather conditions were corrected to read shadows instead a subtle but safety-critical distinction.
These are not edge cases that surface from generic data pipelines. They are the kinds of long-tail scenarios that only structured triage combined with domain expertise can surface, classify, and resolve. That is what makes edge case triage in autonomous systems so powerful for closing real-world performance gaps.
The Human-in-the-Loop Factor: What Automation Can’t Do Alone
Automated detection pipelines can flag low-confidence model predictions, statistical outliers, and sensor anomalies. That is a useful first filter but it has a structural ceiling.
Automated systems cannot identify their own unknown unknowns.
A model that has never encountered a specific type of scenario emits no uncertainty signal about it. It simply fails silently. This is where human-in-the-loop expertise becomes irreplaceable.
iMerit Scholars specialized domain experts trained in AV failure modes, sensor modalities, and edge case taxonomy recognize significance that automated filters miss entirely. A scenario that clears every confidence threshold might still be immediately flagged by an experienced Scholar as a known precursor to model failure. This human-led intelligence is centralized and managed through Ango Hub, iMerit’s purpose-built platform for detecting, routing, and resolving anomalies across the triage workflow.
At iMerit, this combination of automated pre-filtering and expert human review sits at the core of how we approach human-in-the-loop data annotation for autonomous systems clients. The human layer is not a workaround for immature automation it is a permanent, structural component of a trustworthy triage system.
The Triage Workflow: From Raw Data to Retrained Model
Effective edge case triage in autonomous systems follows a disciplined, repeatable three-step workflow not an ad hoc review process.
Step 1: Ingestion and Identification
Raw fleet data is ingested and passed through automated screening. This layer flags candidate events based on:
The output is a candidate pool; a filtered subset of total data that warrants human review. Getting this filter calibrated correctly matters: too permissive and the downstream pipeline is flooded; too strict and genuine long-tail scenarios pass through undetected.
Step 2: Expert Triage
This is the human-in-the-loop judgment layer, structured around iMerit’s three-tier escalation framework ensuring every issue is handled at the right level of depth and expertise:
- Tier 1 – Operational Triage: Rapid intake, classification, and validation of large data volumes. Data specialists focus on structuring incident pipelines, running annotation QA, and filtering noise from high-volume event streams producing clean, validated datasets ready for downstream use.
- Tier 2 – Technical Triage: In-depth investigation of perception failures and system behavior gaps. Analysts trained in autonomous systems use replay tools and multi-sensor data to understand why failures occur, identify anomaly patterns, and surface validated insights for model improvement. This includes:
- Classification: What type of edge case is this? Occlusion, novel object, atypical geometry, environmental anomaly?
- Severity scoring: How likely is this to cause a safety-critical failure in autonomous vehicles?
- Novelty assessment: Is this already in the training set, or does it represent a genuine coverage gap?
- Prioritization: Given current model weaknesses and labeling capacity, what enters the queue first?
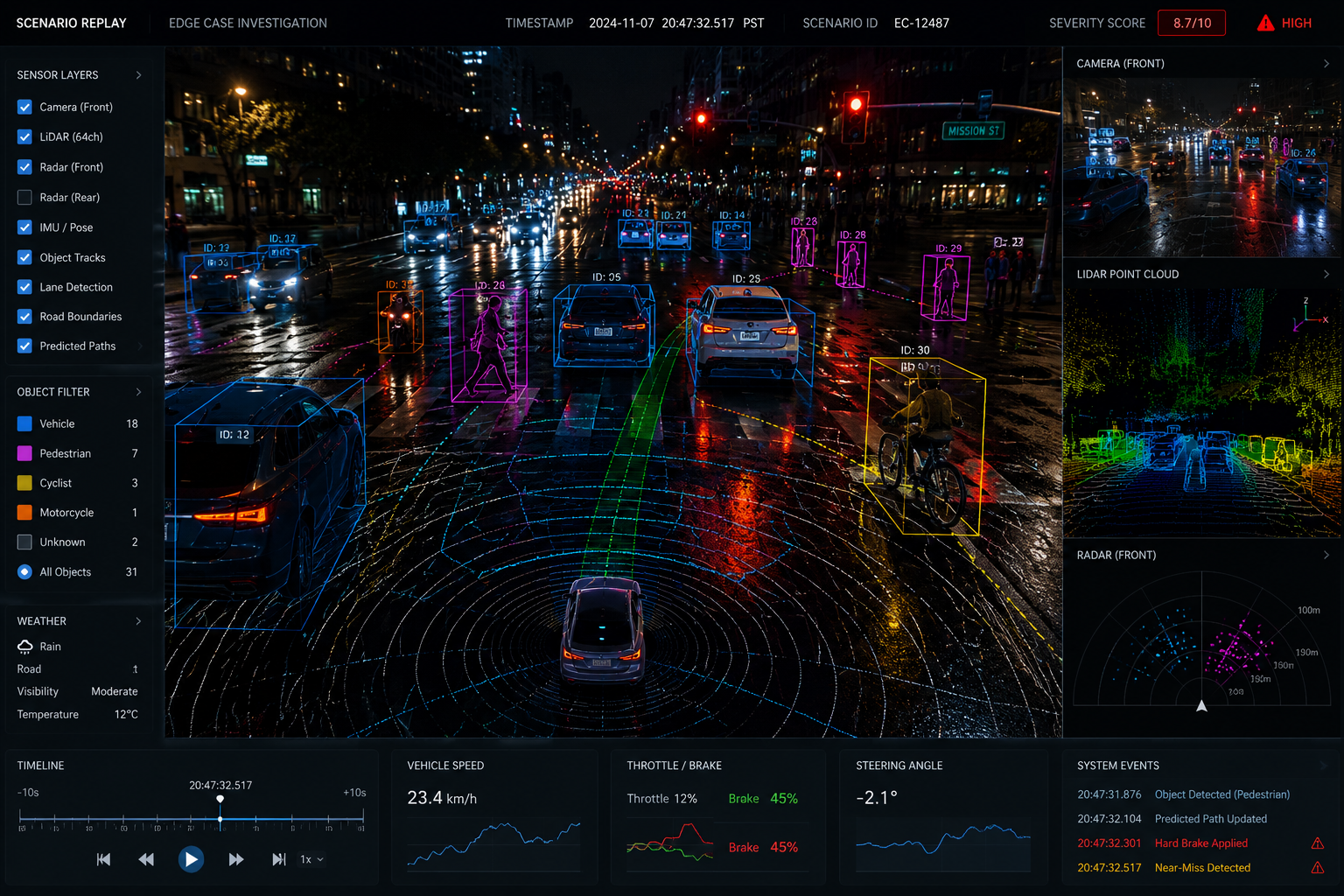
- Tier 3 – Engineering Triage: Full-stack root cause analysis across the autonomy system. Expert engineers diagnose failures at the source across perception, localization, and prediction modules and deliver actionable recommendations that drive engineering resolution.
This structured escalation is what turns an undifferentiated mass of rare events into a navigable, prioritized map of specific failure risks and what enables autonomous vehicles teams to act on triage findings with confidence.
According to industry analysis, edge cases and rare scenario failures remain one of the primary obstacles to deploying autonomous vehicles at scale. Research indicates that models trained predominantly on common driving conditions can fail unpredictably when encountering low-frequency, high-stakes events, commonly referred to as the “long tail” of autonomous driving data. Addressing this gap through systematic data prioritization is now considered essential to achieving SAE Level 4 and Level 5 autonomy.
Step 3: Targeted Retraining for Model Improvement
Prioritized, fully annotated edge cases are fed back into the training pipeline not as random additions, but as strategically weighted inputs designed to close identified gaps. The retraining cycle is then validated against the specific scenarios that motivated it.
This closed-loop approach is what separates triage-informed retraining from generic data augmentation. You know what you fed in. You know what gap you were targeting. And you measure whether it closed. Over multiple cycles, this builds institutional knowledge about how and where autonomous vehicles fail a living taxonomy that informs not just today’s model but future architecture decisions as well.
The Path to Safer Autonomy
The road to Level 4 and Level 5 autonomy will not be won with bigger models or more sensors alone. It will be won by teams that understand precisely where their autonomous vehicles fail and have the discipline and infrastructure to correct those failures efficiently.
Edge case triage in autonomous systems is that infrastructure. Without it, the long tail remains a moving target: as fleets expand into new geographies and conditions, long-tail scenarios multiply faster than undifferentiated data collection can address them. With it, every rare event becomes a training asset, every failure mode becomes a fixable gap, and every retraining cycle becomes a measurable step toward safety. iMerit’s structured triage workflows consistently help clients exceed accuracy thresholds including achieving greater than 95% accuracy in complex 3D LiDAR and semantic segmentation workflows.
Triage is not a preprocessing step that happens before the real AI work begins. It is the engine for continuous model improvement in autonomous systems. The question for teams building toward safer autonomy is not whether to invest in triage, it is how to build a triage capability that scales with their fleet, their model complexity, and the expanding diversity of the real world their systems must navigate.
Ango Hub and iMerit Scholars together provide the precision and confidence needed to move past “more data” and toward the smart data required for Level 4 and Level 5 deployment. Explore iMerit’s Triage Services






















