
Voice cloning technology has advanced quickly in recent years. Earlier voice cloning methods required large datasets and long recordings to recreate a person’s voice.
Today, newer AI systems can generate speech from a short audio clip. This capability, known as “zero-shot voice cloning,” can reproduce tone, accent, and speaking style with remarkable accuracy. Models like VALL-E show just how far speech synthesis has progressed.
However, the ability to mimic voices with less data can also introduce new risks. Fraud actors can replicate human voices without consent and impersonate or manipulate them to spread false information.
Organizations need to go beyond reactive policies and create ethical AI frameworks to address governance concerns. These include consent and identity verification controls and safeguards, such as audio watermarking.
In this article, we explore how ethical frameworks can support the responsible development and deployment of zero-shot voice cloning systems.
What Is Zero-Shot Voice Cloning?
Zero-shot voice cloning is an AI capability that can generate a person’s voice from just a small audio sample. Instead of collecting hours of recordings from a speaker, modern systems can analyze a few seconds of speech and generate new sentences in the speaker’s voice.
Older voice synthesis systems functioned differently. They would usually require large, well-compiled, and carefully recorded voice datasets from a single speaker. Creating these datasets took time and effort. With zero-shot voice cloning, the system is aware of general speech behavior and can quickly adapt when exposed to a new voice.
Several technical advances make this possible:
- Self-supervised speech models that learn patterns in speech from large collections of audio.
- Large generative models capable of producing natural-sounding speech.
- Speaker verification systems that capture distinctive vocal features.
- Real-time synthesis that enables quick speech generation for interactive applications.
The technology is also used in real-world settings. It can support personalized voice assistants, voice restoration for people who can no longer speak, or conservation of endangered languages.
However, cloned voices can also be used as tools in phishing scams, impersonation, or other similar instances.
Organizations need robust controls to mitigate risks associated with voice cloning and ensure ethical behavior.
Authentication and Identity Controls in Zero-Shot Voice Cloning
Since a person’s voice is closely tied to identity, safeguards are important when using voice cloning systems. Many organizations may add governance controls, such as:
- Consent APIs to ensure explicit, verifiable permission before cloning a voice.
- Liveness detection to determine if a voice is from a live human or a synthetic/pre-recorded spoof.
- Identity verification that cross-checks that the voice belongs to the claimed individual.
- Synthetic disclosure standards to indicate synthesized speech. These standards may include audio watermarking or audible markers like accents and pronunciation.
Key Ethical Risks and Challenges
Despite the controls, the rapid growth of zero-shot voice cloning poses several ethical threats. Some risks affect individuals directly, while others influence public trust and the way digital audio is used across systems.
| Individual Harm | Societal Harm | Systematic Risks |
| Invades privacy | Spreads misinformation | Biased or limited training data |
| Causes emotional distress | Erodes trust in audio evidence | Exploits audio samples without consent |
| Enables impersonation and fraud | Misinterprets culture or language | Weak access controls or open APIs. |
1. Individual Harm
Voice cloning is likely to directly affect personal privacy, safety, and identity.
- Privacy Erosion: A person’s voice is a biometric identifier. Voice samples taken from public recordings can be reused without the owner’s consent or knowledge.
- Psychological and Emotional Harm: Hearing one’s own voice in fabricated audio may be disturbing for individuals. This can also damage reputations or create harassment and intimidation.
- Identity Exploitation and Financial Fraud: Attackers can also use cloning as a social engineering tactic. Fraudsters may impersonate business executives or family and friends to trick victims into sharing sensitive information and funds.
For example, fraudsters used AI voice cloning to impersonate a German CEO and convinced a UK company executive to transfer $243,000 to a fraudulent account.
2. Societal Harm
Synthetic voices can influence how information spreads and how people interpret audio evidence.
- Misinformation and Political Manipulation: Hacktivists can use synthetic audio to generate convincing but false statements issued by famous people, mainly politicians. This makes people vulnerable to propaganda campaigns and deception at elections or political events.
- Erosion of Trust in Audio Evidence: Audio recordings have long been treated as reliable evidence in journalism and investigations. People may begin to question whether recordings are genuine as artificial speech becomes more realistic.
- Cultural and Linguistic Distortion: The voice cloning technology may be trained on sparse datasets, and its accuracy may be misinterpreted. It may not represent accents and dialects, or even speak the culture’s language.
For example, an impersonation campaign used cloned audio to mimic the voice of U.S. Secretary of State Marco Rubio to contact officials and spread misleading communications.
3. Systemic Risk
Some risks come from how voice cloning systems are trained, designed, and deployed.
- Bias and Equity Gaps in Training Data: If your training data is limited, the model may not work equally well for everyone. The voice cloning system may reproduce voices poorly for certain accents, dialects, or languages.
- Data Vulnerability and Sample Exploitation: Since zero-shot voice cloning systems can clone a voice from only a few seconds of audio, people may capture samples from interviews or social media clips without the speaker’s consent. This also makes identity verification harder for platforms deploying these tools.
- Infrastructure-Level Security Weaknesses: Weak access controls or open APIs can make misuse easier. Without proper safeguards, attackers may generate cloned voices or run large-scale impersonation attempts.
For example, widely available voice-cloning tools were reportedly used to generate a fake robocall that imitated Joe Biden’s voice during the 2024 New Hampshire primary. This highlights how accessible systems with limited controls can facilitate large-scale impersonation.
Core Principles for an Ethical AI Framework
Building voice cloning systems responsibly requires a few AI safety guardrails. These principles include :
- Consent and Transparency: Always get clear permission before using someone’s voice data. Tell people how their recordings will be used and stored. If your system generates synthetic speech, label it clearly so listeners know the audio is AI-generated.
- Authentication and Identity Validation: Verify who is submitting voice samples. For instance, require identity verification, account verification, or ownership confirmation before a voice can be cloned. That minimizes the likelihood of anyone imitating another person’s voice without permission.
- Technical Traceability: Add technical markers, such as watermarks or metadata tags, to AI-generated audio. They help platforms and investigators trace the audio’s source.
- Fairness and Non-Discrimination: Use diverse voice datasets to train your models. Add other accents, dialects, and languages. Test outputs frequently to check whether certain datasets perform poorly for certain population groups.
- Human-Centric Safeguards: Implement practical controls. Limit the duration of generated audio, restrict high-risk uses, and review suspicious requests. For sensitive applications such as political content or financial communication, add manual approval before the audio is generated.
- Harm Minimization: Before you release new features, ask what can go wrong. Cut out features that can easily be misused, like cloning voices from very brief samples. Begin with safer defaults and expand capabilities only after rigorous testing.
- Red Teaming and Misuse Simulation: Actively test how your system might be abused. Try to break your own safeguards. For example, simulate impersonation attempts or fraud scenarios to see whether your controls actually stop them.
- Continuous Monitoring: Track how your system is used after deployment. Monitor logs, review suspicious activity, and audit outputs regularly. If misuse is detected, you should be able to quickly pause access or adjust safeguards.
Teams that want to strengthen these practices can also work with specialized partners. iMerit offers ethical data annotation and responsible AI workflows that help improve training quality and oversight. It also supports red teaming and RLHF by stress-testing models against real-world misuse scenarios through adversarial evaluation led by domain experts.
Building a Robust Ethical Framework
Applying the above principles to build an ethical framework can be challenging due to evolving risks, technical constraints, and the trade-off between innovation and safety.
Below are general guidelines for addressing such issues and enabling companies to manage risks and protect people’s data.
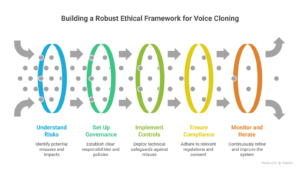
1. Understand the Risks
First, plot out what might go wrong. Consider how someone might misuse a cloned voice, or how the system errors might cause trouble. For instance, could someone clone a CEO’s voice to approve a fake transaction? Could automated calls be used to spread misinformation?
Run a simple threat-mapping exercise. List potential misuses and rate them by likelihood and impact. After that, decide which risk needs immediate safeguards. Tools like the NIST AI Risk Management Framework can guide this process.
2. Set Up Clear AI Voice Governance
Don’t leave decisions to just one team. Both legal and tech teams need to contribute to AI voice governance. Ensure everyone has clear responsibilities and knows exactly who is responsible for policy changes and who must approve new features.
Form a mini cross-functional committee. Meet once a month to review updates or new risks and incidents. Document who is responsible for each action.
3. Enable Technical Controls for Security
Implement technical controls to prevent technology misuse. These may include rate limiting, authentication, and usage monitoring. You can also use tools to detect AI-generated audio. For instance, Respeecher embeds cryptographic content credentials in audio generated on its platform to help verify the file’s origin and detect tampering.
Meanwhile, platforms like Reality Defender and Pindrop help analyze audio signals to identify deepfake speech or voice spoofing attempts.
4. Ensure Regulatory Compliance
Under the EU AI Act, AI-generated content is generally low-risk. This means that labeling or watermarking synthetic voices is required, but high-risk requirements apply only when it’s used for things like biometric ID or fraud detection.
For GDPR, voice biometrics are considered sensitive data. This means you need explicit consent whenever you record, store, or synthesize someone’s voice. Even when creating synthetic voices, think carefully about data minimization.
Decide which applications could be high-risk. If your tool could be used for verification or security, log all usage and run a compliance check.
Moreover, add a consent checkbox that clearly explains how the voice will be used. Keep separate logs of consent and the purpose of the voice recordings.
5. Implement Monitoring and Iteration
Enable continuous monitoring once the system is live. Monitor performance, check for errors or misuse, and refine any defenses you may have enabled. Hold monthly audits. Go over flagged incidents, adjust policies, and test safeguards. Use these findings to tweak the system and lower its risk over time.
Also, track key performance indicators like false positive and false negative rates in fraud detection or synthetic speech detection systems. These metrics show whether the system incorrectly flags legitimate audio or fails to detect manipulated speech.
Balancing Innovation with Restriction
Voice cloning is useful, but it comes with risks. The challenge is to protect people without slowing progress. Too many regulations can make it hard to use these tools. Small research teams or startups may struggle to access them, which could block useful applications from being developed.
At the same time, some uses have clear benefits. For example, voice cloning can help people regain speech after injury, make dubbing movies easier, or improve accessibility for different languages. Regulations should allow these uses while preventing harm.
Moreover, researchers require room to experiment. But open research comes with responsibility. To release tools to the public, teams should test for bias and unpredictability, specify limits, and restrict high-risk uses, such as fraud or biometric ID.
Future Directions and Recommendations
Voice cloning as a field is still developing, with several directions that might make the technology safer and more responsible in the future. These may include:
- Companies can use blockchain to track the origin of voices, which might make it easier to verify authenticity. Federated learning can minimize the storage of sensitive voice data in one location and reduce privacy risks. Either method can enable safer innovation without delaying progress.
- Global standards for voice cloning are still limited. Initiatives such as the C2PA (Content Authenticity Initiative) for audio might help make synthetic content more transparent. Shared rules make it easier for developers to follow best practices across different regions.
- Developers can start with simple, practical steps to protect users. A consent API wrapper ensures that users agree before their voice is used. Limiting cloning requests and embedding watermarks in synthetic audio can prevent misuse. Using a checklist approach makes responsible deployment part of everyday workflows.
Conclusion
Voice cloning can be useful, but it comes with real responsibilities. Teams need to think about consent, privacy, fairness, and the risk of misuse. Clear testing, monitoring, and simple processes help spot problems early and make models behave as expected.
Key Takeaways
- Get consent and be transparent on how you use voice data.
- Check for bias, privacy issues, and errors with simple, reliable measures.
- Keep monitoring your zero-shot voice cloning system because models and data change over time.
- Use technical controls like verification checks, rate limits, and watermarks to stop misuse.
Ready to deploy voice AI safely?
iMerit helps organizations build trustworthy voice AI through services such as audio annotation, RLHF for speech models, and adversarial impersonation testing. With expert-led model evaluation and responsible data practices, you can deploy zero-shot voice cloning with confidence while minimizing ethical and security risks.
Talk to an iMerit expert today!



















