
Artificial intelligence (AI) models don’t always produce accurate, safe, or contextually appropriate responses. They need continuous refinement to better align with human expectations. Reinforcement Learning from Human Feedback (RLHF) plays a key role in this process. It uses human input to guide model behavior, improve response quality, and reduce biases. Without RLHF, AI systems risk generating unreliable or even harmful outputs.
However, scaling human feedback is difficult. Collecting, evaluating, and integrating it manually is inefficient, especially for large models. This is why RLHF tools and automation platforms are essential—they streamline data collection, optimize reward modeling, and ensure AI models learn effectively from human input.
In this article, we’ll explore some of the top tools designed to simplify and enhance RLHF, making AI training more efficient and scalable.
Why RLHF Requires Automation for Scaling AI Training
RLHF is essential for fine-tuning AI models but comes with significant technical challenges. Scaling human annotations, defining effective reward models, and ensuring unbiased, safe outputs require specialized tools and automation. Without these, RLHF can become inefficient, costly, and prone to errors.
Automation platforms address these challenges by streamlining data collection, optimizing reward modeling, and managing large-scale training. Below are some of the key issues in RLHF and how automation helps solve them:
- Human labeling bottlenecks: RLHF relies on high-quality human feedback, but collecting and annotating data at scale is a significant obstacle. Human raters must review thousands of AI-generated responses for relevance, coherence, factual correctness, and safety, which is time-consuming, costly, and prone to inconsistencies and biases. Variability in human judgment can lead to errors in feedback, impacting model training quality. Automation increases efficiency by enabling distributed human-in-the-loop (HITL) workflows, active learning, and dynamic task allocation, reducing manual workload while improving consistency.
- Reward modeling complexity: Defining an optimal reward function is one of the most complex parts of RLHF. Unlike supervised learning, RLHF requires learning from implicit human preferences, which are often subjective and context-dependent. RLHF platforms optimize this process by integrating adaptive reward shaping, reinforcement learning pipelines, and model-driven reward estimation.
- Scaling training for large models: Training large language models (LLMs) with RLHF requires massive computing power and efficient data flow. Moreover, handling large batches of feedback while maintaining efficient training pipelines is a key challenge. Automation tools manage distributed training, dynamic batching, and model parallelism to improve scalability and reduce overhead. They may also use gradient accumulation – a technique to optimize memory usage.
- AI safety and compliance risks: Since RLHF aligns models with human intent, there’s a risk that models learn overly permissive or restrictive behaviors based on flawed feedback. For example, an AI chatbot fine-tuned via RLHF might generate responses that subtly reinforce misinformation or accept harmful queries. Automated monitoring, guardrail enforcement, and policy-driven filtering help detect and correct harmful outputs before deployment.
- Bias in feedback data: Human input is naturally biased, and influenced by cultural, personal, and contextual factors. RLHF can amplify biases over iterations, reinforcing problematic behaviors. RLHF platforms can mitigate these risks using bias detection algorithms, statistical sampling, and adversarial validation techniques.
Top Tools and Automation Platform for RLHF
Automation platforms can help overcome RLHF challenges by streamlining data labeling, quality control, and feedback integration. These tools provide essential features to optimize RLHF processes, making it easier to fine-tune models efficiently.
Below are some of the most commonly used tools and automation platforms for RLHF.
1. iMerit Ango Hub
iMerit Ango Hub enhances AI model performance through RLHF by supporting large-scale human-in-the-loop processes, making it a scalable solution for optimizing LLMs, large vision models (LVMs), and foundation models. It provides tools for data correction, model auditing, and quality control, enabling AI teams to assess model responses, apply corrective measures, and align outputs with intended objectives.
With a focus on automation and expert-driven evaluation, iMerit Ango Hub offers tools for data correction, model auditing, and quality control. AI teams can assess model responses, apply corrective measures, and align outputs with intended objectives. The platform also integrates workflow automation, model APIs, and reporting features to streamline the RLHF process.
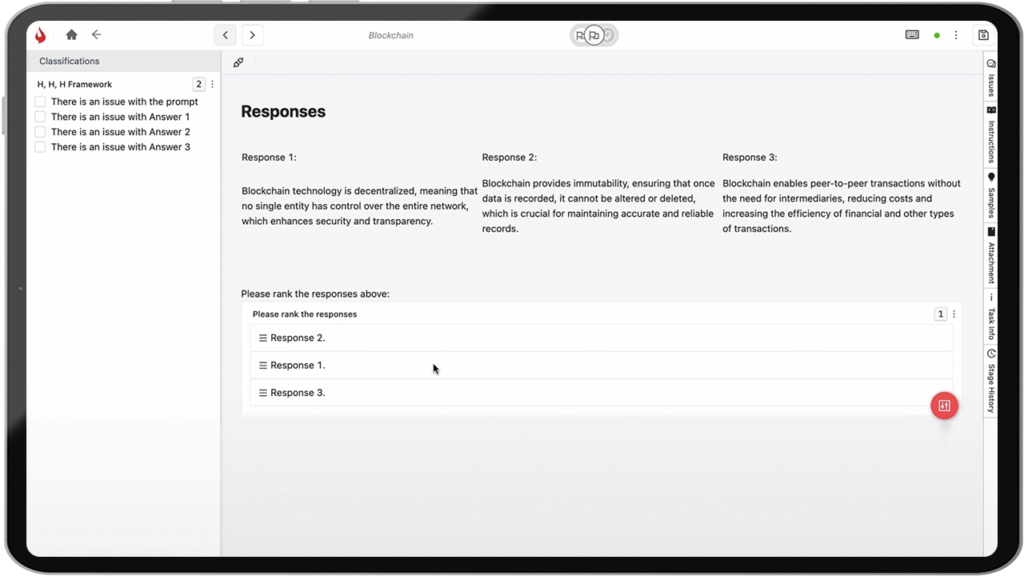
The Rank Tool in Ango Hub is suitable for projects requiring evaluation and prioritization of assets. Annotators can use this tool to rank different media types, including text, images, and videos.
Moreover, iMerit provides access to a global network of domain experts and skilled annotators. They refine training data, improve model alignment, and ensure high-quality outputs.
Key features
- Provides expert annotations, scoring, and corrections to improve model accuracy.
- Supports model alignment with custom evaluation metrics and human feedback.
- Automates RLHF workflows with scalable data pipeline management.
- Includes auditing and quality control tools to refine training data integrity.
- Offers integration with model APIs, annotation tools, and reporting dashboards.
- Provides AI-assisted labeling to automate repetitive tasks and boost efficiency.
- Delivers real-time performance analytics for monitoring and optimizing workflow progress.
- Supports multiple annotation types, including bounding boxes, polygons, key points, and semantic segmentation.
- Ensures scalability for large-scale RLHF projects.
- Secure and GDPR, HIPAA, ISO 27001, and SOC 2 compliant platform.
2. Encord RLHF
Encord RLHF is a collaborative platform that enhances RLHF for LLMs and vision-language models (VLMs). It provides tools to streamline content moderation, chatbot optimization, and model evaluation, ensuring AI systems align with human preferences.
The platform also supports data labeling and curation through specialized workforces, improving data quality for training and evaluation. Encord RLHF integrates with various cloud storage providers and offers enterprise-grade security.
Key features
- Enables chatbot optimization by aligning outputs with human feedback.
- Supports content moderation by helping LLMs detect and flag misinformation, hate speech, and spam.
- Provides benchmarking, ranking, named entity recognition, and classification tools to evaluate model performance.
- Facilitates high-quality data labeling and curation through specialized RLHF experts.
- Offers enterprise-level security with SOC2, HIPAA, and GDPR compliance.
3. Appen RLHF
Appen RLHF enhances LLM performance by integrating human feedback into reinforcement learning workflows. It enables AI models to improve through iterative evaluations from a curated pool of domain experts. Appen ensures models generate responses that align with user intent and real-world expectations by supporting single-turn and multi-turn conversations.
With real-time human interactions, direct preference optimization (DPO), and customizable annotation workflows, Appen RLHF helps refine AI-generated responses to improve accuracy, coherence, and adherence to guidelines.
Key features
- Access to expert annotators who provide high-quality feedback for RLHF.
- Robust quality control mechanisms to detect gibberish content and duplication.
- Multi-modal data annotation support for text, images, audio, and more.
- Real-world simulation environments for context-aware training.
- Benchmarking tools with transparent performance tracking for model evaluation.
4. Toloka AI
Toloka AI is a crowdsourced data labeling platform that supports RLHF workflows for fine-tuning large language models. It provides real-time human feedback to improve AI-generated responses, helping models align with human preferences.
With a diverse expert community spanning 20+ knowledge domains and 40+ languages, Toloka enables scalable, high-quality annotations for AI training. Its RLHF capabilities include preference ranking, human-in-the-loop evaluation, and benchmarking solutions to refine AI models through iterative feedback loops.
Key features
- Offers real-time human feedback for RLHF and preference optimization.
- Provides multi-turn and single-turn conversation datasets for fine-tuning.
- Supports inter-annotator agreement metrics for quality assurance.
- Features automated quality control and fraud detection with 50+ methods.
- Ensures compliance with ISO 27001, SOC 2, GDPR, CCPA, and HIPAA standards.
5. Labelbox
Labelbox improves AI model alignment through RLHF and DPO. It enables AI teams to train models using high-quality human-generated data, ensuring outputs align with user expectations.
Labelbox addresses common challenges in RLHF, such as inconsistent human feedback, bias, and high operational costs. It offers scalable tools for data labeling, real-time quality control, and expert human evaluation.
Key features
- Provides access to a network of expert AI trainers for high-quality preference data.
- Supports RLHF and DPO workflows for improved model alignment.
- Offers real-time quality control and performance tracking.
- Includes tools for bias mitigation and human-centric evaluation.
- Streamlines RLHF workflows to reduce costs and training time.
6. Scale
Scale is an AI platform that optimizes LLMs through RLHF. It enables AI teams to refine model responses by leveraging high-quality human feedback, improving model accuracy and alignment with user expectations.
The platform provides a scalable infrastructure for human-in-the-loop training. It supports various AI applications, such as chatbots, content generation, and code generation. Scale’s interface simplifies the feedback process, allowing annotators to rank, verify, and compare model outputs.
Key features
- Supports RLHF to optimize LLM performance with human input.
- Provides an intuitive user interface for streamlined feedback collection.
- Offers collaborative tools to enhance communication between labelers and model trainers.
- Ensures high-quality annotations through a specialized expert workforce.
- Scales efficiently to handle large datasets for AI model training.
7. Surge AI
Surge AI is a data labeling and RLHF platform that trains LLMs, including Anthropic’s Claude. It provides high-quality human feedback for tasks like summarization, copywriting, behavior cloning, and model alignment, helping improve AI safety and response accuracy.
The platform offers easy integration through APIs and SDKs, making it accessible for teams developing chatbots, generative AI tools, and other LLM applications. With enterprise-grade security, Surge AI ensures safe and reliable model training.
Key features
- Supports InstructGPT-style model training with human feedback.
- Provides SOC 2-compliant security for enterprise-level data protection.
- Offers API and SDK integration for seamless workflow automation.
- Features human evaluation tools to assess and improve model behavior.
- Includes a managed service option with expert data teams for custom AI projects.
Comparative Analysis of RLHF Tools
Below is a comparative analysis of various RLHF tools, highlighting key features, compliance, and use cases.
| Tools | Workforce & Expertise | Best for | Key Features | Compliance | Use Cases |
|---|---|---|---|---|---|
| Merit Anno Hub | Skilled, trained domain workers with expertise in healthcare, automotive, and AI data | Organizations seeking skilled data annotation and RLHF services | Auto-assisted labeling Auto-labeling with ML models Multi-format data support Quality control mechanisms |
SOC 2 Type II ISO 27001 ISO 19115 GDPR HIPAA TISAX |
AI data pipeline support Text and complex data workflows Healthcare, medical, autonomous vehicles, NLP and NER |
| Encord RLHF | AI researchers and developers seeking to leverage domain expertise to enhance LLMs performance | Same as left | Auto-assisted labeling Active learning Dataset bias detection |
GDPR SOC 2 |
Healthcare Agriculture Natural language processing (NLP) and RLHF |
| Appen RLHF | Crowdsourced and managed workforce for large-scale projects | Enterprises requiring data at scale | Multimodal data annotation Quality reports Customizable QA plans |
ISO 27001 SOC 2 Type II |
NLP and data labeling |
| Toloka AI | Distributed workforce with built-in human validation | AI teams needing scalable data annotation and validation | Multi-sense human validation Support for various RLHF algorithms Automation Quality control |
ISO 27001 GDPR CCPA HIPAA |
Text and image evaluation, data collection, and data labeling |
| Labelbox | Internal teams or outsourcing via labeling platform | Teams focusing on ML evaluation and automated data labeling | Model-assisted labeling (MAL) Real-time quality control Expert human evaluation |
ISO 27001 SOC 2 Type II GDPR HIPAA |
Text, video, image annotation Model evaluation |
| Scale | Hybrid approach: ML-driven | Organizations requiring high-quality data | Multi-format annotations: images, videos, etc. | ISO 27001 SOC 2/FEDRAMP-High |
Data labeling and annotation |
| Surge AI | Expert crowd workers, linguists, and domain specialists | Teams developing safe, responsible LLMs via multi-step pilots and reviews | Infrastructure LIDAR, text, etc. Combines ML algorithms with human oversight Customizable QA workflows InstructGPT-style model labeling API and SDK integration Human evaluation tools |
Authorized SOC 2 Type II | Summarization, copywriting, and behavior cloning |
Takeaway
RLHF is essential for improving AI models, aligning them with human intent, and ensuring safe, high-quality outputs. However, it comes with challenges like scaling human feedback collection, mitigating bias, and maintaining compliance. To overcome these complexities, leveraging specialized tools and automation platforms is crucial.
iMerit Ango Hub provides an end-to-end RLHF solution to streamline data pipelines, enhance annotation processes, and optimize model performance.
Learn how a leading Asian technology company used iMerit’s RLHF services to fine-tune its LLM-powered AI chatbot, improving its adaptability and response quality.
Why choose iMerit for RLHF?
- Expert-led data annotation: Access a global network of domain experts for high-quality training data.
- Scalable RLHF automation: Implement human-in-the-loop feedback at scale to improve model accuracy.
- Quality audits and data correction: Assess model outputs, apply corrections, and improve dataset integrity.
- Benchmarking and guidelines: Custom benchmarks and detailed guidelines keep performance uniform.
- Comprehensive reporting and analytics: Track feedback, model improvements, and training data efficiency.
With iMerit’s expert-driven workforce of 5,500 annotators and access to 2,000+ language experts and scholars, we provide high-quality, scalable RLHF solutions tailored for LLMs, VLMs, and foundation models. Our automation capabilities, compliance standards, and deep industry expertise make us the ideal partner for organizations looking to enhance model performance efficiently.
Ready to enhance your AI model with RLHF?
iMerit provides the expertise, tools, and automation needed to refine AI models efficiently. Talk to an expert to explore how our RLHF services can accelerate your AI development.





















