
An AI-generated video can look convincing at first glance. The characters are detailed, the lighting feels natural, and the motion appears smooth, but after a few seconds, something breaks. A face subtly changes shape, a hand gains or loses fingers, a background object shifts position between frames, and the illusion collapses.
This instability is known as temporal drift in AI-generated video. It describes the loss of visual, spatial, or semantic consistency across consecutive frames. A model may produce high-quality individual images, yet fail to maintain coherence over time.
For enterprises deploying production AI systems, this is more than a visual flaw. Temporal drift undermines AI-generated video quality, weakens trust, and limits scalability. As video models evolve into multimodal AI systems, solving temporal consistency is foundational to building reliable, production-ready video AI.
In this article, we explore the causes of temporal drift, methods for evaluating and benchmarking AI-generated video, the role of video data annotation, and strategies for reducing drift in production AI and multimodal systems.
What Causes Temporal Drift in AI-Generated Video
Temporal drift in AI-generated video arises from how generative models predict frames over time. Video models typically generate frames sequentially. Each new frame depends on the model’s representation of previous frames. When this representation becomes incomplete or slightly inaccurate, inconsistencies emerge.
Several technical factors contribute to this behavior.
Short-Term Memory Limitations
Most video generation models operate with a limited temporal context. They only retain information from a fixed number of previous frames when generating the next frame.
Once earlier frames fall outside this context window, the model relies on compressed representations instead of detailed visual information. Important attributes such as character structure, object placement, or scene layout may not be preserved precisely. As the sequence progresses, these small inaccuracies propagate forward and gradually affect visual continuity.
Weak Cross-Frame Alignment
Maintaining spatial consistency across frames is essential for stable video generation. Objects and characters must remain aligned with their previous positions while still reflecting natural movement.
When cross-frame alignment mechanisms are weak, spatial relationships begin to shift between frames. Objects may slightly change shape or location, and characters may appear unstable during motion. These small alignment errors introduce flickering or subtle movement artifacts that disrupt temporal coherence.
Training Data Gaps
Temporal stability also depends heavily on the structure of training data. Many video datasets contain short clips or lack detailed annotations that link objects and identities across frames.
Without consistent temporal signals during training, models struggle to learn how visual elements should persist over longer sequences. This limitation makes it difficult to maintain stable object identities and scene structure when generating extended video outputs.
Temporal Drift Challenges in Multimodal AI Systems
Multimodal video models generate sequences by combining several input signals. These typically include text prompts, visual references, motion patterns, or audio cues.
The multimodal nature makes it difficult to prevent temporal drift in AI-generated video across frames while preserving AI-generated video quality.
Text to Video Alignment Challenges
Text prompts act as the primary instruction for many multimodal video systems. They define the scene, actions, and objects that the model should generate over time. The model converts these textual instructions into a sequence of visual frames.
A key challenge is that the prompt remains static while the video evolves. For each new frame, the model conditions on the prompt and previously generated frames. Small deviations in earlier frames can accumulate across the sequence, causing deviations in the visual content.
Cross-Modal Inconsistency
Multimodal systems combine signals from different sources, and these signals do not always align perfectly during generation. Text prompts describe the scene, reference images define appearance, and audio inputs may guide speech or timing.
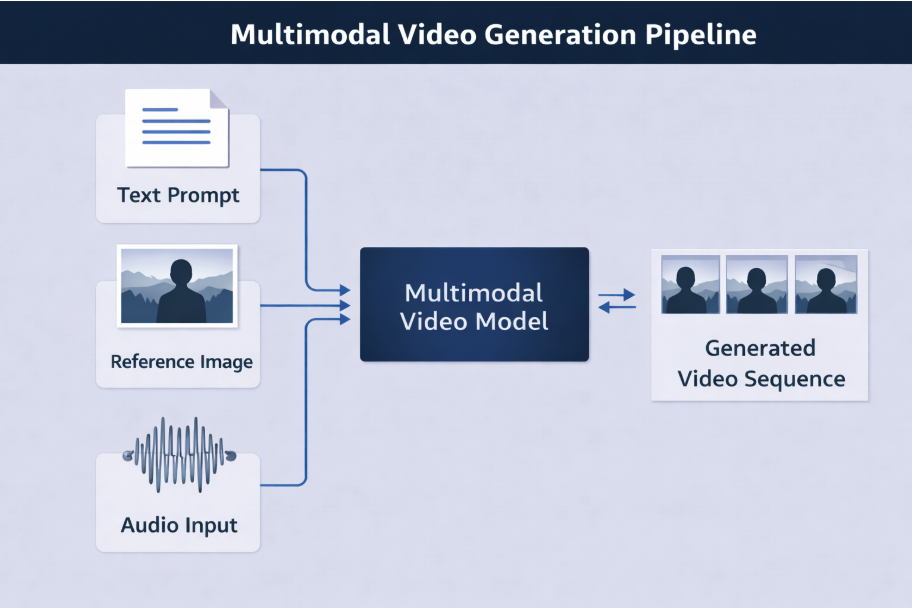
Each modality influences the generation process. When the model assigns unequal weight to these signals, inconsistencies can appear in the output. For example, visual appearance may remain stable while actions deviate from the prompt, or the audio narration may not align with the visual sequence.
Evaluation Complexity in Multimodal System
Evaluating temporal consistency becomes more complex when multiple modalities influence the generated video. Traditional evaluation methods often assess visual quality at the frame level, whereas multimodal systems require consistency across multiple dimensions.
Failures in multimodal systems may occur within a single modality or across modalities. Frame-level evaluation cannot detect issues that develop across consecutive frames or capture relationships between modalities such as audiovisual alignment, object movement, or character identity consistency.
Detecting these issues requires sequence-level evaluation methods. These approaches analyze the full video sequence to assess visual continuity, prompt adherence, and audiovisual alignment in addition to other quality metrics.
Architectural Solutions to Reduce Temporal Drift in AI-Generated Video
Recent advances in generative video architectures aim to reduce temporal drift by improving how models process information across frames. These improvements focus on preserving object identity, maintaining motion stability, and coordinating multimodal inputs during generation.
Memory-Augmented Models
Temporal memory mechanisms allow models to retain information from earlier frames while generating new frames. They often use transformer-based architectures to model long-range temporal dependencies.
The Temporally Consistent Transformer (TECO) architecture shows that incorporating temporal attention across frames improves long-term coherence in generated videos. This approach compresses frame representations into embeddings and applies temporal transformers to maintain consistency across long video sequences.
Cross-Frame Consistency
Some mechanisms enforce visual stability between consecutive frames. Many modern video generation systems incorporate spatio-temporal modeling to capture relationships between objects and motion across frames.
The StoryDiffusion framework proposes consistent self-attention and semantic motion prediction modules. The framework stabilizes subject identity and improves long-range coherence in generated videos.
Multimodal Coordination
The multimodal nature of video models makes it difficult to align input signals with the generated output. Some architectures address this by modeling the entire video sequence simultaneously instead of predicting frames independently.
The Lumiere text-to-video model introduces a space-time diffusion architecture that generates the full temporal sequence in a single pass. It processes spatial and temporal information jointly through a space-time U-Net architecture, maintaining consistent motion across frames.
Evaluating Temporal Drift Through Video Model Evaluation and Benchmarking
Despite recent advances in architecture, evaluating temporal drift remains a persistent challenge in video generation systems. Small inconsistencies go undetected, especially in longer sequences or complex scenes.
To address this issue, enterprises rely on sequence-level video model evaluation and structured video model benchmarking. Insights from these processes help refine training datasets through targeted video data annotation and iterative data curation pipelines that label drift-prone scenarios.
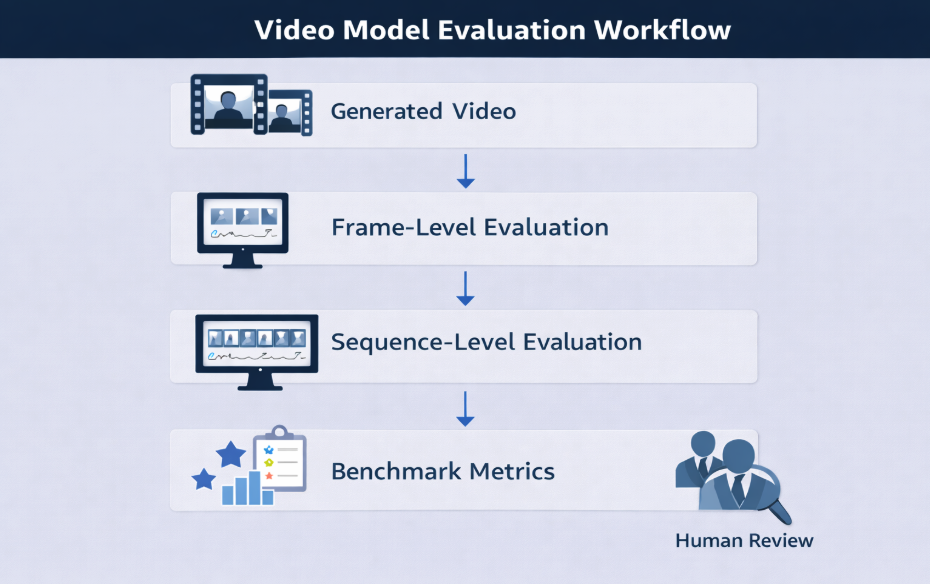
Frame vs Sequence Evaluation
Frame-level evaluation measures visual quality in individual frames using image-based metrics. The method helps detect artifacts, blur, or distortion in a single frame.
However, temporal drift can manifest through gradual identity shifts, motion inconsistencies, or scene changes across frames. Frame-level evaluation cannot detect such issues since it evaluates each frame independently.
In contrast, sequence-level evaluation analyzes frames as a continuous sequence to check if object identity and motion patterns remain consistent. It also ensures scene structure coherence, providing a more reliable measure of model performance.
Metrics for Video Model Evaluation
Modern video evaluation frameworks combine multiple metrics to measure different aspects of temporal stability. These metrics typically focus on identity persistence, motion continuity, and scene coherence.
Common metrics include:
| Metric | What It Measures | Purpose in Temporal Drift Evaluation |
| Fréchet Video Distance (FVD) | Distribution similarity between generated and real video sequences | Evaluates overall visual and motion realism across sequences, identifying large-scale temporal drift |
| LPIPS (Perceptual Image Patch Similarity) | Perceptual similarity across generated and reference frames | Detects subtle appearance changes and identity drift across consecutive frames |
| STREAM (Spatio-Temporal Evaluation and Analysis Metric) | Separately evaluates spatial fidelity and temporal naturalness | Identifies inconsistencies affecting motion stability and visual continuity |
These metrics allow researchers and engineering teams to compare model versions and identify where temporal drift emerges during video generation.
Sequence Level Benchmarking
Sequence-level benchmarks are crucial for production AI systems that need stable video over long sequences. Applications like simulation, training content, film previsualization, and interactive storytelling rely on consistent object identity and motion.
Benchmarking uses standardized datasets to test stability across longer sequences rather than just short clips. Modern benchmarks evaluate challenging scenarios, including complex motion, multi-object interactions, camera movement, and changing environments. These tests help reveal weaknesses that short clips or simple prompts may miss.
Several recent benchmarks have been introduced to evaluate generative video models more systematically.
| Benchmark | Focus |
| VBench | Temporal consistency, motion realism, visual quality, prompt alignment |
| EvalCrafter | Appearance, motion, text alignment |
| T2V-CompBench | Object composition, actions, spatial relationships |
| T2VEval-Bench | Realism, technical quality, text-video consistency |
These benchmarks provide standardized evaluation protocols. They allow researchers and engineering teams to compare models and identify where temporal drift appears during generation.
Human Review
Automated metrics provide valuable signals, but they cannot capture every form of temporal inconsistency. Subtle identity shifts, unnatural motion, or semantic errors may still appear realistic to automated systems.
Human reviewers play an important role in identifying these issues. Expert evaluators can detect inconsistencies in character identity, motion realism, and prompt alignment that automated metrics may overlook.
Combining automated evaluation with structured human review provides a more comprehensive approach to detecting temporal drift and improving overall video model performance.
The Role of Video Data Annotation in Reducing Temporal Drift
Architectural improvements and evaluation frameworks help detect and measure temporal drift, but training data quality determines how well models learn temporal stability
High-quality video data annotation provides structured temporal signals that guide model learning in ways described below.
Temporal Linking Across Frames
Temporal linking connects the same object or identity across consecutive frames in a video sequence. Instead of labeling objects independently in each frame, annotation pipelines track objects throughout the entire clip.
This approach helps models learn continuous motion patterns and spatial relationships over time. For example, tracking a moving vehicle or a walking person across frames teaches the model how object position, orientation, and scale change during motion.
Persistent Identity Tagging
Persistent identity tagging ensures that the same object or character retains a consistent label across frames. Without identity continuity, models may treat the same subject as different entities when its appearance changes slightly over time.
For instance, a person turning their head, moving through shadows, or partially leaving the frame should still be recognized as the same identity. Consistent labeling reinforces this continuity and helps models maintain stable identities across longer sequences.
Edge Case Curation
Edge cases often expose weaknesses in temporal learning. Situations such as partial occlusion, fast motion, camera movement, or sudden lighting changes can cause models to lose track of objects across frames.
Curating datasets that include these scenarios improves model resilience. Annotated examples of complex motion patterns or temporary visibility loss teach models how objects behave under challenging conditions, reducing the likelihood of temporal drift during generation.
Feedback Loops
Evaluation insights play an important role in improving annotation pipelines. When benchmarking reveals recurring temporal inconsistencies, teams can analyze the underlying training data to identify gaps.
These insights guide targeted updates in video data annotation. Additional samples can be labeled for challenging scenarios, and identity linking rules can be refined. This feedback loop between evaluation and annotation gradually strengthens the dataset and helps reduce temporal drift in future model iterations.
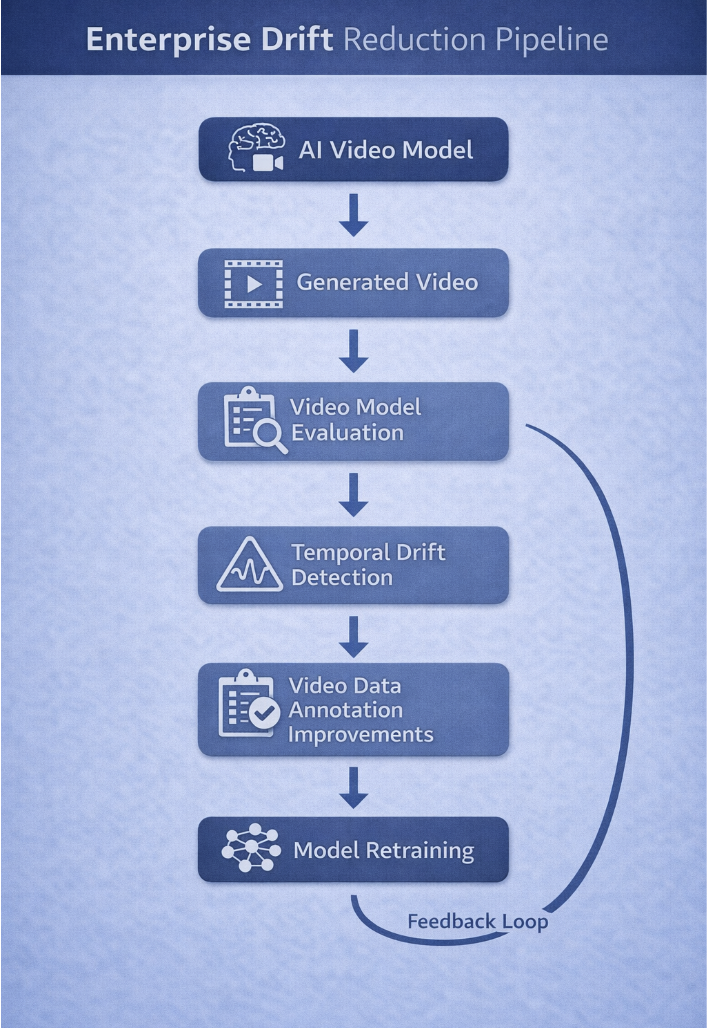
Addressing Temporal Drift in Production AI Systems
Temporal drift becomes critical when video generation systems move from experimentation to production AI systems. In enterprise environments, unreliable outputs can affect system performance, user trust, and operational workflows.
Organizations deploy structured pipelines that combine monitoring, drift thresholds, and human oversight to detect and correct inconsistencies early. Automated evaluation and expert review prevent drift from propagating in large-scale deployments.
Monitoring Drift and Drift Thresholds
Production AI systems continuously monitor generated sequences to track identity persistence, motion continuity, and scene coherence. Alerts are triggered when deviations exceed application-specific thresholds.
Tailoring thresholds to each application’s criticality ensures stable video quality without overburdening the workflow. For example, minor drift may be tolerable in marketing or social media content, while simulations, training videos, or enterprise operations demand near-perfect consistency.
Integrating Evaluation and Annotation
Evaluation and annotation processes work together to improve temporal stability. Evaluation frameworks identify patterns of drift across generated sequences, while annotation pipelines address the underlying data gaps that contribute to these issues.
When evaluation metrics consistently detect identity shifts or motion instability, teams can examine training datasets to determine whether specific scenarios are underrepresented. Additional annotated samples can then be introduced to strengthen the model’s learning in those situations.
This integration creates a continuous improvement loop where evaluation insights guide dataset updates and annotation strategies support more stable model behavior.
Human Oversight
Human reviewers can analyze generated sequences and identify patterns that require correction. Their feedback helps refine evaluation criteria, adjust drift thresholds, and guide targeted improvements in training datasets.
Expert review programs, such as iMerit Scholars, provide specialized oversight of complex AI systems, enabling organizations to integrate automated monitoring with domain expertise. This approach helps maintain consistent video quality while supporting continuous model improvement in production environments.
How iMerit Supports Temporal Stability in AI-Generated Video
Despite the above practices, maintaining temporal stability in AI-generated video can be difficult due to data limitations, model complexity, and subjective human evaluation. A platform like iMerit can provide enterprises with end-to-end support to enable these workflows, ensuring that models remain reliable across long sequences and complex multimodal inputs.
Advanced Video Data Annotation
iMerit’s video annotation services offer structured, high-quality data labeling for AI models. Expert annotators label objects and scenes across video frames using bounding boxes, polygons, keypoints, and semantic segmentation to create reliable training datasets.
Production-Ready Human-in-the-Loop Support
Even with advanced evaluation and annotation, human oversight is critical. iMerit provides production-ready human-in-the-loop workflows where subject-matter experts monitor outputs, correct drift, and feed insights back into models. This continuous feedback loop enhances model performance, maintains consistency across sequences, and ensures high-quality video generation for enterprise applications.
Conclusion
Temporal drift in AI-generated video is a reliability challenge that directly affects production scalability, enterprise trust, and model performance. Even with modern architectures, long-sequence consistency cannot be fully guaranteed without structured evaluation and high-quality video data annotation. Reducing drift requires sequence-level benchmarking, clear monitoring thresholds, and expert human oversight.
Key Takeaways:
- Temporal drift in AI-generated video describes the loss of visual, spatial, or semantic consistency across frames.
- Sequence-level video model evaluation and video model benchmarking help detect identity shifts, motion instability, and scene inconsistencies.
- High-quality video data annotation improves temporal learning through temporal linking, persistent identity tagging, and edge-case coverage.
- Production AI systems require monitoring pipelines, drift thresholds, and human oversight to maintain consistent video quality.
Connect with iMerit to strengthen temporal stability in your AI video systems. Implement robust evaluation workflows, scale expert video annotation, and build production-ready AI-generated video that performs consistently over time.


















