
Most AI models struggle when they face new or unusual situations. They can’t always adapt well, which limits how useful they are in the real world. That’s why we need smarter ways to train them. One approach that’s gaining traction is Reinforcement Learning from Human Feedback (RLHF). It brings human judgment into the training process, which helps AI make better decisions in tough or unclear scenarios.
For example, Tencent introduced a new RLHF framework called Reinforcement Learning with Label-sensitive Reward (RLLR) to help models learn more effectively. RLLR performed 1.54% better on average than traditional supervised fine-tuning models in natural language understanding.
Accurate data labeling also plays a huge role. For multi-sensor systems, like those used in self-driving cars, precise annotations are everything. Companies like iMerit are helping lead the way by providing labeled data for 3D point clouds, LiDAR, and more. When RLHF is added to the mix, the models become even more reliable. This blog discusses how RLHF enhances multi-sensor object detection and scene understanding by integrating human feedback into AI training workflows.
System Architecture & Sensor Fusion
How a system is built tells us a great deal about how it functions in the real world. Sensor fusion plays a key role by combining data from different sources. Let’s look at its main components and how they work together.
Multi-Sensor Inputs
Multi-sensor object detection relies on integrating data from heterogeneous sources. Here are a few of them:
- LiDAR (Light Detection and Ranging): Acquires 3D spatial data and offers depth maps and structural outlines useful in localizing objects.
- Cameras (RGB): Provide high-resolution texture and color details and can be used to enable semantic segmentation, classification, and visual context interpretation.
- Radar: Helps estimate velocity and predict motion. It works well in poor weather (rain, fog, low light).
- GPS/IMU: Delivers global position information and inertial measurements of the orientation that trace the object trajectories and register different frames.
Sensor Fusion Methods
Sensor fusion strategies should be tailored to optimize the value of diverse sensors. Popular strategies are:
- Early Fusion: The raw data provided by several sensors is combined before feature extraction. This can preserve maximum information but is computationally demanding and vulnerable to synchronization errors.
- Feature-Level Fusion: Features extracted in one modality are fused in the middle of the pipeline. It is a standard option in deep learning architectures, allowing the system to acquire cross-modal correlations.
- Late Fusion: The sensor-specific models are trained separately, and the decision is combined during inference. This method is modular and interpretable, but it can ignore inter-modal dependencies.
iMerit Contribution
As RLHF relies heavily on high-quality data and precise feedback workflows, iMerit provides the infrastructure and expertise to support each pipeline stage. Let’s have a look:
Complete Workflow Versioning & Real-Time Iteration
Ango Hub is a data annotation platform developed by iMerit. It includes workflow versioning, reviewer logic customization, and real-time iteration. Users can create multi-stage pipelines, designate reviewers at different stages, and track performance in real time. It integrates real-time issue logs and performance dashboards to maintain consistent quality in dynamic projects.
Scale HITL
iMerit combines a global annotator workforce with SME-led review layers, handling escalations (e.g., “reject → reassign”) via custom reviewer pipelines. Such a model is particularly useful in reward modeling in RLHF, where subtle human judgment is essential.
Synchronization of 3D + Video
iMerit offers a powerful multi-sensor fusion capability by registering 3D LiDAR data to video and RGB images on a common platform. With sophisticated 3D tools, annotators can tag synchronized data with high spatial and temporal precision. The platform is highly format-friendly and well-suited for autonomous vehicles, robotics, and other applications that use multiple sensors. This results in more detailed and accurate data.
RLHF Integration Framework
Training perception models with RLHF is a multi-stage training objective. The RLHF pipeline improves traditional perception models through feedback, reward construction, and policy refinement. This integration unfolds in several phases.
Let’s have a look at each phase:
Initial Supervised Model
The initial point is a robust supervised baseline. The model can be an object detector or semantic segmentation network. It is pre-trained with large-scale labeled datasets. The pre-alignment phase involves training on this baseline. During this stage, the model is tuned on metrics such as bounding-box IoU or pixel accuracy. Techniques such as data augmentation (e.g., random weather effects or simulated occlusions) can enhance the robustness of the model. Multi-sensor augmentation (e.g., combining LiDAR and camera perturbations) also reinforces the pre-alignment model.
Human Feedback Collection Loop
When the baseline model has been deployed in a test environment, a feedback loop can be initiated. The model takes scenes as input and generates outputs (lists of detected objects, segmentation maps, etc.). The assessment can be of various types:
- Direct Scoring: A human observer compares the model’s output to the sensor data and assigns a score (e.g., 1-5) based on its quality. The score can be low if the model fails to detect a visible object, and it’s the same when it flags something irrelevant.
- Error Detection: The reviewer may specifically indicate errors (e.g., “missed pedestrian at position (x,y)” or “false alarm on tree shadow”), which can be turned into a negative reward signal on those particular outputs.
The quality of data is critical throughout the loop. Versioning tools record which model version generated the outputs and what batch of data it used. This ensures that feedback is connected with the proper context. Additionally, active learning can be applied when deciding which frames should be sent for human review. When human effort is focused specifically on these high-value cases, it leads to a significant reduction in the overall labeling volume.
Reward Model Construction
The reward model is generally a neural network that accepts as input some representation of:
- State: The sensor data of the scene or features learned by the backbone of the perception model.
- Actuation: Collection of predicted bounding boxes, classes, or the segmentation mask.
It then produces a scalar reward value. This value shows the degree of satisfaction with the output based on human response. Pairwise comparisons are commonly employed to train the reward model. Here is the process diagram for reward model training:
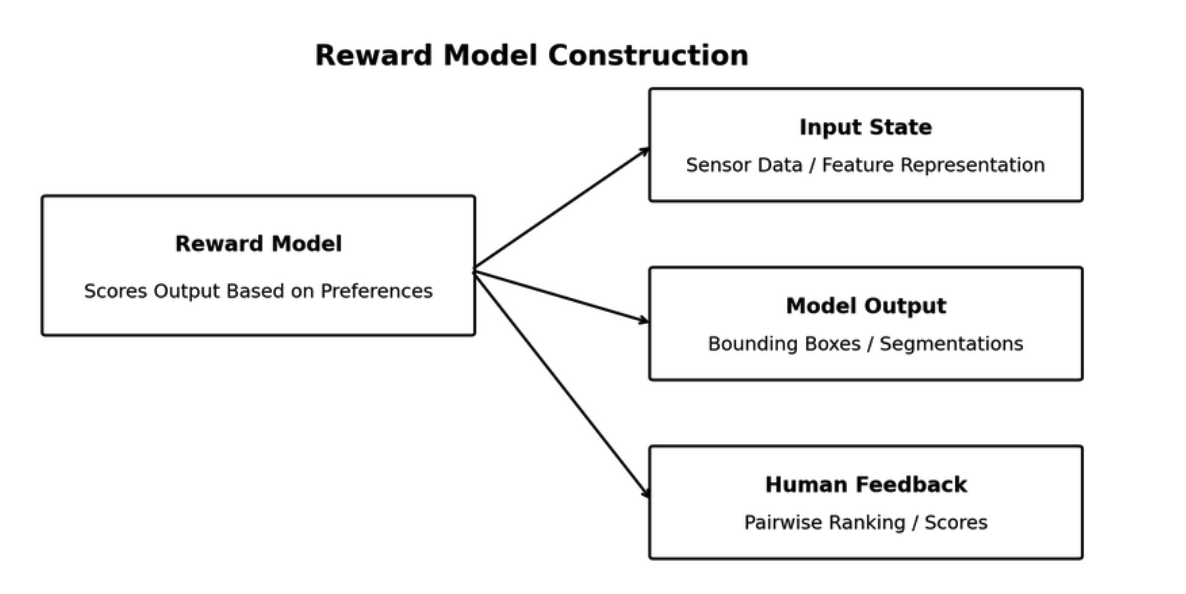
Consider a model that gives two outputs in response to a single input (A and B). When a human provides feedback that “A is preferred over B,” the reward model will be tuned to give a high score to A over B. If direct scoring feedback is used, the reward model can be trained through regression.
Adding some kind of regularization or smoothing to the reward model is also common. It should not get too closely tailored to the training comparisons. Otherwise, it will tend to map extreme rewards to peculiar outputs that only delighted a single annotator.
The reward model must be generalized across similar cases. This prevents overfitting to the human feedback. iMerit allows a scalable collection of high-quality human feedback through structured workflows, including direct scoring and pairwise preference ranking.
Policy Fine-Tuning via RL
An algorithm commonly used in RLHF is Proximal Policy Optimization (PPO). PPO is a steady policy-gradient algorithm that iteratively updates the policy but ensures that the changes are within a safe range. A restriction can also be introduced to prevent the policy from departing from the initial model. This restriction is commonly enforced in the form of the Kullback-Leibler divergence penalty.
Another technique known as Direct Preference Optimization (DPO) can simplify fine-tuning. DPO does not use conventional reinforcement learning updates. Instead, it modifies the model directly based on preference data. It achieves this without an explicit reward loop. DPO chooses a loss function based on preference probability.
However, reward hacking behavior should be monitored during RL fine-tuning. Reward hacking occurs when an agent discovers unintended means of maximizing reward. For example, the detection model may learn to slightly increase the bounding box area.
This may mislead the reward model into believing that object coverage is improved, but it actually worsens localization. As mitigation, engineers can occasionally ask humans to check some of the outputs of the RL-updated model.
When a policy is overoptimized to the peculiarities of the reward model, it can be worse in the uncovered scenarios. Techniques such as early stopping or reduced learning rates can avoid overfitting. Mixing a small amount of the initial supervised loss can keep the model neutral.
This step results in a post-alignment perception model. The architecture of this model is identical to the original, but its parameters have been adjusted to show human-aligned behavior.
Ideally, it will continue to detect everything it detected before. But this time, it will also process situations that used to be troublesome in a much more human-expectant way.
Evaluation and Benchmarking
Structured evaluation criteria evaluate RLHF’s success in developing multi-sensor perception. This framework compares detection accuracy, contextual understanding, and human alignment with baseline models.
Ango Hub’s benchmark feature supports this evaluation by enabling gold-standard task comparison to quantify annotator and model alignment performance across metrics like IoU and classification consensus.
Here is the evaluation and benchmarking diagram summarizing key metrics to assess RLHF model improvements.
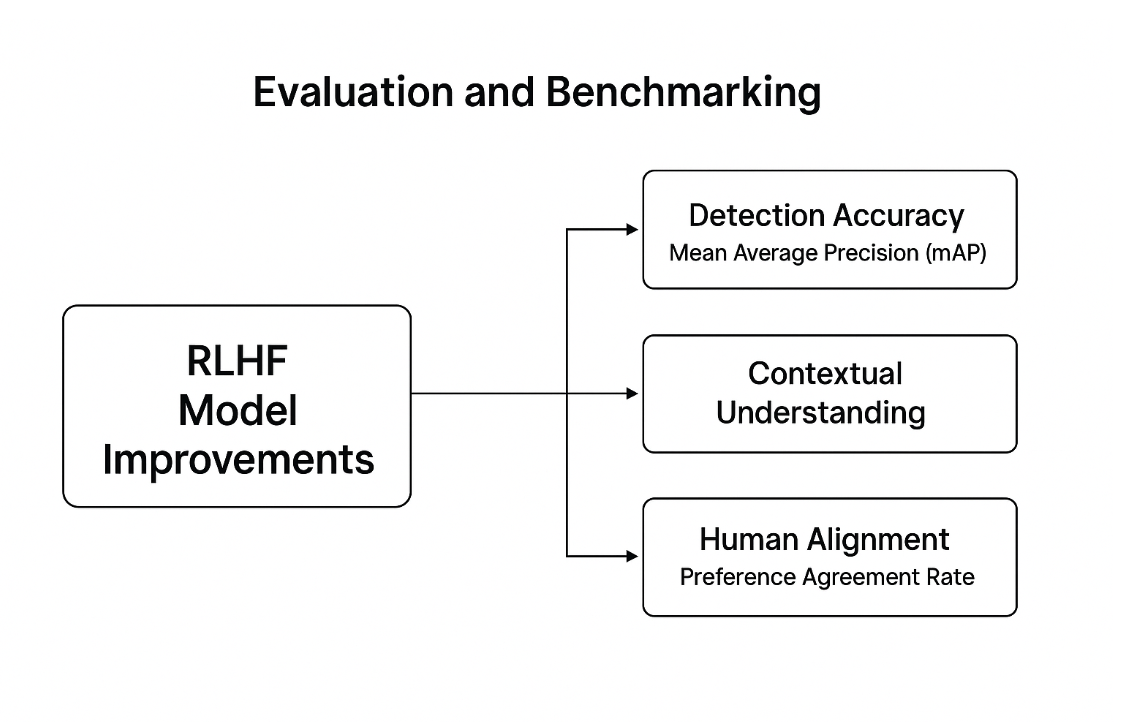
Common Detection Evaluation Measures
The baseline analysis of RLHF-boosted models starts with detection metrics. Mean Average Precision (mAP) evaluates the accuracy of detections across object classes, reflecting localization and classification accuracy.
An increase in these measures after RLHF indicates improved performance, particularly in noisy or ambiguous tasks.
Scene-Level Understanding
Multi-sensor models must move beyond detecting isolated objects to scene interpretation. Scene-level metrics evaluate the model’s performance in spatial relations and contextual relevance recognition.
For example, identifying a pedestrian at a crosswalk or a car overtaking another vehicle. RLHF allows models to learn these subtle hints, making it more consistent with human reasoning in rich settings.
Post-RLHF Improvements vs. Baseline
The effect of RLHF is evaluated by comparing pre- and post-training outputs. Significant milestones are:
- Improvements in mAP and recall in challenging conditions (e.g., night, rain, occlusion)
- Decrease in false positive and negative results
- Better uniformity between geographic and operational differences
Such comparisons demonstrate the practical usefulness of RLHF.
Human Feedback Alignment Scores
RLHF learns with human preferences. The model is then trained to measure its alignment with those preferences. The preference agreement rate demonstrates the frequency of coincidence between the model result and a human’s choice.
The reward model’s ranking accuracy is also tested to confirm it ranks preferred outputs higher than rejected ones. Techniques that improve annotation quality and decision consistency, such as consensus logic and escalation workflows, play a key role in this process. These scores ensure that the model indeed learned human feedback properly.
High alignment implies that the model can make decisions that convey expert intent, particularly in situations of uncertainty or complexity.
Operational Constraints & Mitigation Strategies
Deploying RLHF-enhanced perception models in real-world systems presents practical challenges that extend beyond training accuracy. This section outlines key operational constraints and presents strategies to ensure performance, safety, and scalability in production environments.
Deployment in Production Systems
Bringing RLHF-enhanced models into real-world deployment requires addressing several production-level concerns. Here are a few of them:
- Scalability: Autonomous vehicles and robots have edge devices that continuously process sensor data. RLHF should enable low-latency decision-making without computational overhead.
- Domain Transfer: Perception systems deal with changing weather, lighting, terrain, and sensor calibration. RLHF should enable models to adapt to new domains without requiring retraining. This demands various training sets and frequent feedback in unknown environments.
- Versioning: All the updates (in the base model, the reward function, or the feedback dataset) should be monitored. Version control production systems must have strict version control to ensure both safety and debugging, and pass regulatory audits.
Common Challenges
Despite the benefits, RLHF presents several issues that need to be addressed to ensure the reliability and production alignment of models.
- Reward Model Fragility: Reward models can learn spurious patterns when trained with noisy or biased feedback. This gives rise to reward hacking, in which the model learns to maximize the reward signal, regardless of its actual performance.
- Feedback Inconsistency: Human ratings can vary due to experience, context, or fatigue. Divergences among annotators generate noise. Failure to resolve may result in the model learning inconsistent or misleading behaviors.
- Cognitive Load on Annotator: Reviewing detection and scene interpretations in different modalities is cognitively demanding. Inadequate tool and label design confuse the labeling standards, leading to increased errors and poor-quality feedback.
Mitigation Strategies
Effective mitigation requires model-level interventions and human-centric processes to ensure the robust and scalable deployment of RLHF.
- Active Learning: Select examples with high model uncertainty for human review. This strikes feedback where it is most useful, decreases overall labeling work, and enhances learning efficiency.
- Adversarial Training: Feed the reward model deliberately challenging or noisy inputs. This makes it more resistant to edge cases and avoids overfitting trivial patterns in feedback data.
- Planned Retraining and Validation: Both the perception and reward models should be regularly updated with new human feedback. Using validation sets, test alignment, and look at drift. This sustains performance when the environment, sensors, or user expectations vary.
Case Studies
The following case studies show how RLHF and expert-driven annotation workflows enhance multi-sensor perception in real-world applications.
Case Study 1: 3D Perception System LiDAR Annotation iMerit-Powered LiDAR Annotation
One of the prominent companies in autonomous vehicles engaged with iMerit to annotate a large multi-sensor dataset. iMerit developed a rigorous training program to train annotators. With their Multi-Sensor Data Labeling Tool, they annotate objects, lanes, and road boundaries across modalities.
These carefully selected datasets were used as a starting point for supervised training and RLHF feedback loops. iMerit’s human-in-the-loop assistance and alignment training shows a scalable route to bringing RLHF-enhanced perception models to production-ready autonomous vehicles.
Case Study 2: Overcoming 3D Sensor Fusion Labeling Challenges for Autonomous Vehicles
To support advanced multi-sensor perception in autonomous vehicles, iMerit deployed a specialized team of over 2,500 annotators trained in LiDAR, camera, radar, and audio data labeling.
iMerit adopted a tool-agnostic approach, enabling seamless integration with client platforms or proprietary tools. Custom workflows were developed to accommodate varying sensor characteristics, while real-time quality control systems ensured annotation consistency at scale.
This data pipeline facilitated the supervised training and reward-model calibration stages of RLHF, which allowed AV perception models to perform better spatial reasoning and contextual alignment. The project also showed scalable, production-ready annotation of complex sensor fusion systems in live deployment scenarios.
Real-World Applications
Real-world deployments show how human feedback improves model behavior in edge cases that traditional training often overlooks. Here are a few of them:
- Construction Zones: Annotators provide feedback to non-standard lane patterns and structures, which the model can learn during fine-tuning.
- Mixed-Traffic Alignment: RLHF-trained lane-changing policies can be used to work safely with human drivers, decreasing unpredictability.
- Smart Feedback: eBay uses real user behavior to power RLHF in machine translation, marking a shift from lab tests to live impact. Their models learn from clicks in multilingual search, which helps improve accuracy in ways that traditional star ratings often miss.
Conclusion
RLHF enhances the robustness and flexibility of multi-sensor perception models by using human feedback during learning. It allows systems to be more capable in real-world, complex environments.
Key Takeaways
- RLHF enhances edge case detection and contextualization.
- Human input helps models generalize across domains and conditions.
- Reward models align outputs with expert preferences.
- iMerit supports high-quality annotation and feedback processes.
- RLHF can be deployed at a production scale.
Maximize the potential of RLHF in your perception systems by collaborating with specialists in high-quality, multi-sensor annotation and feedback workflows. iMerit provides the specialized support needed to scale, align, and deploy safer, smarter AI for real-world environments.
Discover how RLHF can elevate your multi-sensor models. Contact us today to explore practical applications.



















