
Large Language Models (LLMs) are significantly impacting the way we interact with technology. These powerful AI tools are reshaping industries and transforming how we communicate, learn, and work. Their real power, however, lies in aligning outputs with human values and expectations. This is where Reinforcement Learning from Human Feedback (RLHF) plays a crucial role.
RLHF is a training method that allows human experts to guide the development of LLMs by providing feedback on the model’s outputs. This human-in-the-loop approach has proven invaluable in refining LLMs, helping them align more closely with human preferences and ethical standards. Yet as LLMs scale in complexity and volume, traditional RLHF workflows are under growing pressure, demanding faster, more scalable solutions. The RLHF process takes time and effort, and Artificial Intelligence (AI) and automation advancements can play a significant role here.
The Bottlenecks of RLHF
While RLHF has been instrumental in improving LLMs, it has its limitations. The traditional RLHF relies on human evaluators to assess LLM outputs. The current process relies heavily on human evaluators, which introduces several bottlenecks. Let’s take a look:
- Scalability:
One of the most pressing issues of RLHF is scalability. LLMs generate vast amounts of output, and the task of manually evaluating each response is increasingly daunting, time-consuming, and resource-intensive. This process can slow down the pace of LLM fine-tuning, especially when working with larger models or tackling more complex tasks. - Subjectivity:
Another pressing concern is subjectivity. Despite their expertise, human evaluators bring their preferences and biases to the table, which can lead to inconsistencies in the feedback provided to the LLM. This potentially results in unclear signals that confuse the model during training. - Expertise:
High-quality evaluation often requires domain-specific knowledge. Not all evaluators possess the expertise to assess nuanced LLM outputs, especially in specialized domains like medicine, law, or science. The limited availability of qualified experts slows down the RLHF process and hinders rapid model refinement. - Reward Model Drift:
As the RLHF-trained model evolves, the reward function may become outdated, misaligning with updated policy behaviors. The reward model is typically trained once and does not dynamically adapt unless retrained, leading to reward signal misalignment over time. - Feedback Latency:
The lag between collecting feedback and incorporating it into the model training cycle can delay alignment. This becomes a bottleneck in dynamic or real-time use cases where fast iteration is critical.
How Platforms and AI Are Evolving RLHF Workflows
By leveraging expert-driven human-in-the-loop solutions combined with efficiency-focused platforms, it is possible to unlock more streamlined methods for developing LLMs.
- Enhanced Evaluation Processes
Human experts supported by robust annotation platforms, such as iMerit’s tools, can analyze model outputs for specific criteria like factual accuracy, coherence, or adherence to safety guidelines. Platforms like Ango Hub can simplify the process by enabling experts to collaborate effectively, ensuring consistency in evaluations. Features like real-time task tracking and review versioning further accelerate iteration. - Targeted Feedback Mechanisms
Human evaluators’ expertise can be optimized using platforms that intelligently prioritize outputs for review. These platforms can incorporate task management algorithms that strategically assign critical or ambiguous model outputs to human evaluators. This ensures the most valuable human expertise is focused on the areas of greatest need.
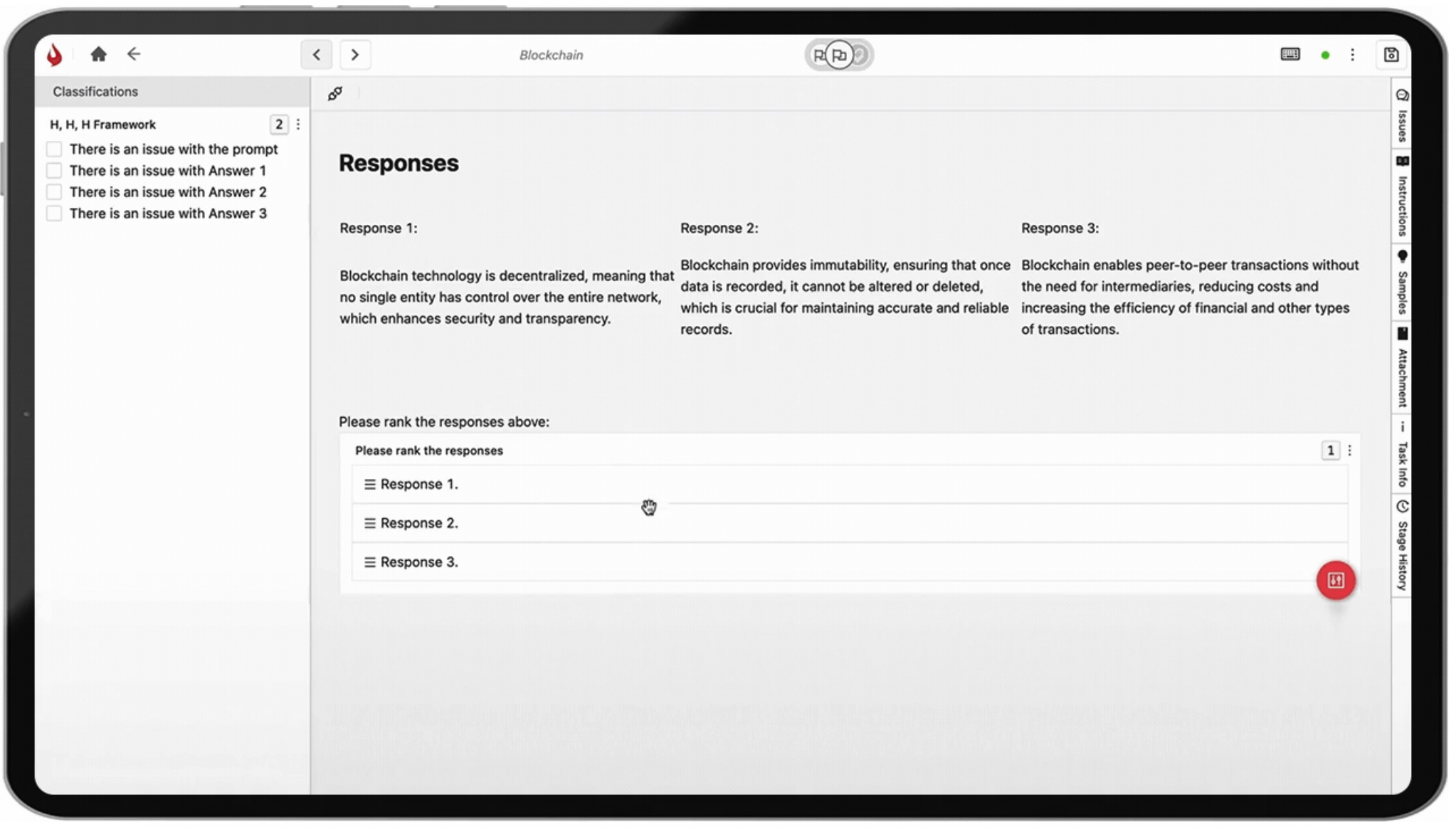
- Reduced Subjectivity with Frameworks
To minimize subjectivity, standardized evaluation frameworks can guide human annotators. These frameworks ensure evaluators adhere to consistent metrics for judging LLM outputs, reducing biases, and improving the reliability of the RLHF signal. - Explainable AI for Transparency
Integrating explainable AI (XAI) capabilities helps human evaluators understand how LLMs arrive at specific outputs. This added transparency enables more accurate, nuanced feedback and supports deeper insights into model behavior, critical for safety-aligned training. - Democratizing LLM Development
Democratizing LLM development involves optimizing workflows to enable participation by evaluators with varying levels of expertise. With structured task flows and layered quality checks, platforms like Ango Hub allow non-experts to contribute effectively by focusing on scoped tasks, while expert reviewers oversee final validation. This expands the talent pool and speeds up data pipeline execution.
Benefits of Enhancing RLHF for LLM Development
By enhancing RLHF with expert-driven solutions and platform-based efficiencies, organizations can realize the following benefits:
- Faster Development Cycles: Automating feedback generation and selection can significantly speed up the RLHF process. This allows researchers to iterate faster and experiment with a wider range of LLM training techniques.
- Improved Scalability: Automating tasks frees up human resources, allowing RLHF to be applied to even larger and more complex LLMs. This opens doors for the development of next-generation foundation models with broader capabilities.
- Reduced Costs: Automation can significantly reduce the manpower required for RLHF, leading to cost savings in LLM development. This makes the technology more accessible to a wider range of organizations.
- Enhance Accuracy and Consistency: AI-powered evaluation ensures LLMs are trained on high-quality feedback, leading to more reliable and trustworthy outputs.
- Stronger Safety Alignment: Continuous human-AI collaboration ensures that safety, compliance, and fairness metrics evolve with the model, leading to better real-world alignment.
The Future of RLHF
The integration of AI and automation offers significant promise for transforming RLHF. We are moving toward continuous learning loops where feedback, evaluation, and fine-tuning happen dynamically, not just during training, but across a model’s lifecycle. With the ongoing advancement of AI techniques, we can anticipate increasingly advanced tools capable of analyzing and evaluating LLM outputs with greater precision and nuance. This progress will lead to the creation of LLMs that are more powerful, dependable, and trustworthy, benefiting a diverse array of applications.
iMerit’s RLHF solutions integrate human-in-the-loop expertise with platform-driven automation, enabling scalable and efficient LLM training. iMerit Ango Hub streamlines RLHF with advanced task automation, customizable workflows, and intelligent data management. It allows organizations to tailor annotation processes, prioritize critical outputs, and enhance feedback consistency. By enabling real-time iteration, version control, and data transparency, Ango Hub supports continual learning cycles and stronger model alignment. By combining expert evaluation with platform-driven efficiencies, we help accelerate LLM development while ensuring alignment with human values and ethical AI standards.
Connect with us today!


















