
AI progress is often framed as a story of better models, larger architectures, improved benchmarks, and faster inference. These advances dominate demos and headlines, creating the impression that stronger models naturally translate into better AI systems. In practice, this assumption rarely holds once AI reaches production. When AI systems are deployed in real-world environments, they encounter conditions far removed from controlled datasets. Data is noisy and incomplete. Edge cases appear at scale. Context shifts over time. Decisions carry operational, financial, and regulatory consequences. At this stage, model performance alone is no longer enough.
For teams responsible for deploying and maintaining AI systems in real-world environments, the challenge is not building models; it is keeping AI reliable after deployment. What ultimately determines whether AI works consistently in the real world is not just the model, but the data operations supporting it.
Why Models Alone Don’t Survive Production
In research and pilot settings, models are evaluated on static datasets with clearly defined labels and boundaries. Production environments are fundamentally different.
Real-world data evolves continuously. Rare scenarios become routine. Inputs that were never seen during training suddenly matter. Even high-performing models begin to degrade under these conditions.
When failures occur, teams often respond by retraining or replacing the model. While sometimes necessary, this response overlooks a deeper issue: most production failures are not caused by model limitations, but by weaknesses in how data is handled after deployment.
Without structured systems to monitor, review, and correct data, AI systems fail quietly. Errors accumulate. Biases go undetected. Performance looks acceptable until a critical breakdown occurs.
Production-grade AI requires operational systems designed for long-term reliability, not short-term performance.
What Production-Grade AI Actually Requires
Calling an AI system production-grade AI implies more than deployment or scale. It implies reliability under real-world conditions.
In practice, production-grade AI must:
- Deliver consistent outcomes across diverse and evolving data
- Handle ambiguity without forcing false confidence
- Adapt as data distributions shift
- Surface uncertainty and risk when decisions are unclear
- Meet operational, regulatory, and customer expectations
This shifts the focus from peak accuracy to behavioral stability. The key question becomes not just how accurate the model is, but how the system behaves when it encounters uncertainty, edge cases, or failure. Answering that question requires mature data operations.
The Role of Data Operations in AI Systems
Data operations form the backbone of production-grade AI. They govern how data flows through the system before, during, and after model inference.
This includes:
These processes are especially critical in regulated, safety-critical, and high-impact AI systems, where errors cannot be treated as isolated incidents.
When data operations are weak or fragmented, AI systems become unstable. When they are well designed, AI systems remain dependable even as conditions change.
Why Human-in-the-Loop Is Not Optional
Automation is essential for scale, but it has clear limits. Certain decisions cannot be resolved through rules or probabilities alone. Context, intent, and real-world nuance often require human judgment.
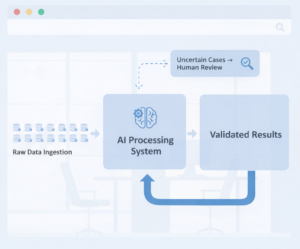
Human-in-the-loop systems introduce structured oversight where automation falls short. They enable:
This kind of operational oversight is central to how iMerit supports enterprise AI teams, helping them scale human judgment alongside automated pipelines to maintain reliability in production.
In production-grade AI, human involvement is not a temporary bridge to full automation. It is a permanent requirement for systems that must operate reliably and responsibly. The challenge is not adding humans into the workflow, but designing processes that scale judgment without compromising quality.
Quality Is a Process, Not a Metric
Offline metrics such as accuracy or precision provide limited insight into real-world performance. In production, quality is defined by systems and processes, not by scores alone.
Effective data operations embed quality control throughout the AI lifecycle. They monitor patterns over time, detect drift early, and prevent silent failure. They also create auditability and traceability, essential for high-stakes and regulated use cases. This process-driven approach ensures that AI systems remain reliable long after deployment.
The Operational Layer Behind AI: MLOps and Data Pipelines
Behind every production-grade AI system is an operational layer that connects models, data, and evaluation processes in a continuous loop. This is where MLOps and AI data pipelines become critical. MLOps frameworks ensure that models can be versioned, monitored, retrained, and governed consistently. Data pipelines manage how raw inputs are ingested, transformed, validated, and routed through annotation, review, and evaluation workflows.
Without structured pipelines, even well-designed data operations become fragmented. Drift goes undetected. Quality signals fail to reach retraining cycles. Human review becomes reactive instead of systematic. Strong AI data pipelines integrate:
- Automated data validation and routing
- Escalation mechanisms for uncertain predictions
- Version control for datasets and annotations
- Monitoring systems that surface performance degradation early
When MLOps and data operations work together, AI systems move from experimental to operationally resilient.
Data Operations as a Strategic Advantage
Organizations that succeed with production-grade AI treat data operations as a core capability rather than a supporting function.
Strong data operations allow teams to:
- Deploy AI with lower risk
- Identify and correct issues earlier
- Adapt systems without rebuilding from scratch
- Build trust with customers, partners, and regulators
While models may differentiate products in the short term, data operations determine whether AI systems can sustain performance over time.
Conclusion: Why Data Operations Decide AI Success
As AI moves from experimentation to real-world deployment, the gap between promising models and reliable outcomes becomes increasingly clear. Production-grade AI is not achieved by optimizing models in isolation. It is achieved by building robust data operations that can handle ambiguity, scale judgment, and maintain quality over time.
This is where many AI initiatives struggle. Organizations underestimate the operational complexity required to support AI in production and overestimate what automation alone can deliver. iMerit helps organizations bridge this gap.
With deep expertise in AI data operations, human-in-the-loop systems, and quality assurance workflows, iMerit enables enterprises to operationalize AI reliably across complex, real-world environments. From data annotation and validation to ongoing evaluation and governance, iMerit supports the lifecycle required to move AI from prototype to production with confidence.
For teams building AI systems that must perform at scale, under scrutiny, and over time, success depends on more than models. It depends on the data operations behind them, and on partners equipped to deliver them.





















