
Enterprises rely more than ever on AI to make decisions, automate tasks, and improve efficiency. However, even the most advanced AI models can fail if not properly tested. MIT’s Media Lab research indicates that 95% of AI projects fail, especially during deployment. Small mistakes in data or evaluation can lead to
major issues such as wrong credit risk decisions, misdiagnosed medical cases, or unsafe automation outputs, all of which carry serious business and compliance consequences.
But how do enterprises know if their AI systems are working well? The answer lies in the gold standard evaluation.
Gold standard evaluation sets are carefully created with high-quality data that experts verify. They help businesses test and improve their AI models before deploying them in real-world applications. Without these AI evaluation tools, companies risk deploying AI systems that may give wrong results, damage customer trust, or fail to meet regulations.
Let’s explore why gold standard evaluation sets matter and how to build them to drive real business value.
What Are Gold Standard AI Evaluation Sets?
In machine learning, an AI system relies on different types of data at various stages of development:
- Training data: Used to teach the model how to make predictions.
- Validation data: Used to fine-tune model parameters during development.
- Evaluation data: Used to measure final performance against trusted AI benchmarking.
Within evaluation data, a gold standard evaluation set forms the benchmark for accuracy and reliability. It is the reference point against which all models or systems are tested. For example, medical images might be annotated by certified radiologists or legal documents reviewed by domain experts. This makes the gold‑standard set a very reliable “ground truth” for measuring model performance.
Not all evaluation sets qualify as a gold standard. They must be carefully curated, relevant to the model’s purpose, and representative of the real-world conditions where the AI will operate.
Without a true gold standard evaluation set, enterprises risk silent failures. Models may appear accurate in testing but fail in real-world use. Research has shown that even widely used benchmark datasets contain nontrivial labeling errors, with an average error rate of around 3.3% in some popular computer vision and NLP test sets. This can lead to poor decisions, unexpected errors, or biased outcomes.
Why Enterprises Need Gold Standard AI Evaluation Sets
Enterprises need gold standard evaluation sets because AI only performs well when tested on high-quality
data. These datasets are especially important in industries that require high precision, like healthcare,
finance, insurance, and autonomous systems.
Poor model performance in such industries can cause significant financial losses, regulatory issues, biased
decisions, or safety hazards.
Gold standard evaluation sets are a strong defense against these risks. Here is how they help:
- Accuracy benchmarking
Gold standard datasets are labeled by experts and validated with care. They give a reliable picture of how
accurate a model truly is. They also help you spot small errors that ordinary test sets often miss. - Bias detection and fixes
Expert-checked data can reveal bias that automated or crowdsourced labels might miss. By reviewing model
performance across different groups, teams can spot unfair patterns and correct them. - Regulatory transparency
Sectors like finance and healthcare require clear, auditable evaluation practices. Gold standard datasets
provide reliable benchmarks that support compliance and explainability. - Trust among stakeholders
When executives or end-users know the AI has been tested on high-quality, trusted data, they are more
likely to trust its results. This boosts confidence during deployment.
How Evaluation Sets Support the Entire AI Lifecycle
Gold standard evaluation sets form the backbone of enterprise AI at every stage. During model training and
tuning, they provide accurate feedback and help developers to refine algorithms and optimize performance.
After deployment, these sets enable ongoing monitoring and revalidation to detect performance drops, data
drift, or emerging edge cases.
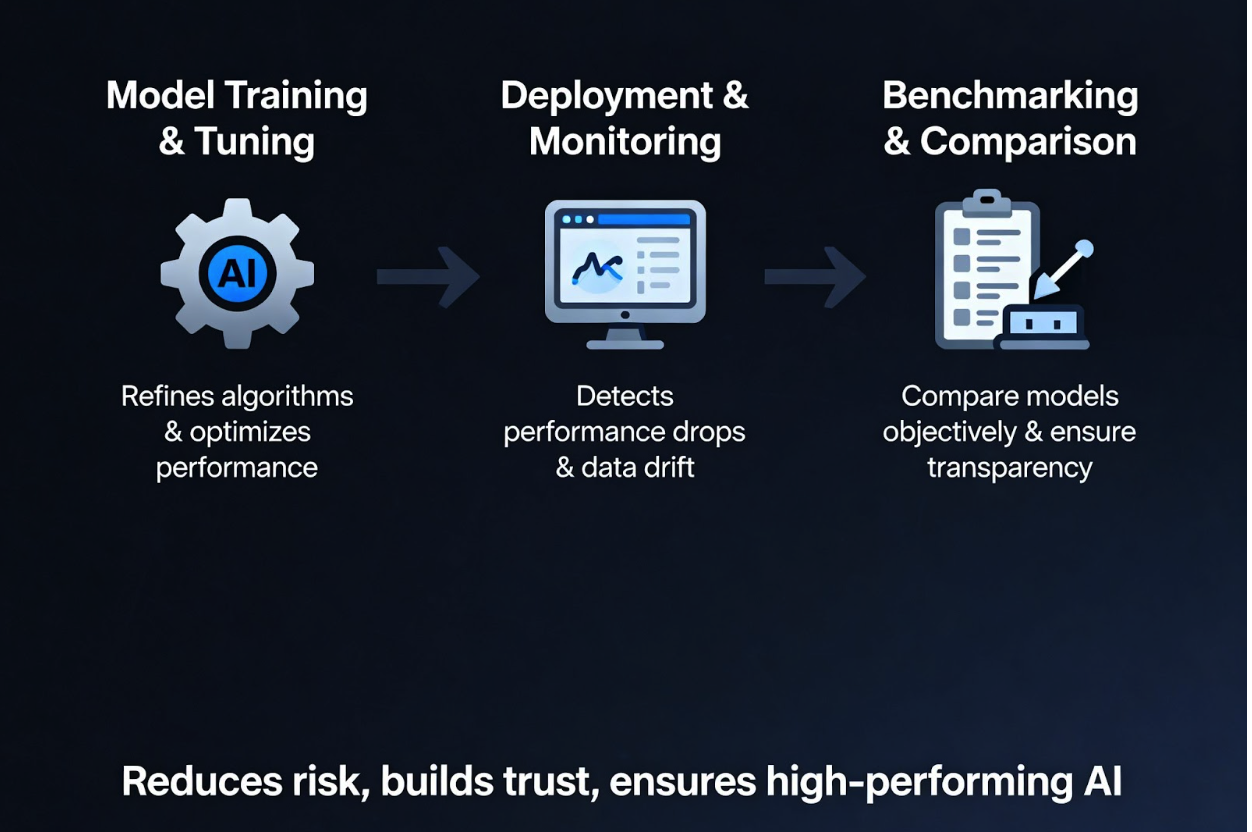
They also serve as an objective benchmark for comparing internal models or vendor solutions, providing better transparency and a more reliable selection process. By providing consistent and expert-validated data, evaluation sets reduce risk and build trust across stakeholders. This makes them important for sustainable and high-performing AI systems.
What Makes an AI Evaluation Set “Gold Standard”?
A gold standard evaluation set is a carefully engineered asset designed to reflect real business conditions
and high-risk scenarios with precision. Several qualities define it:
- Data quality: Each data point is carefully labeled and verified by experts. This ensures the model is tested on correct information.
- Expert labeling: Guidelines are followed strictly during labeling. This reduces errors and ensures the dataset behaves predictably.
- Version control: Every item in the dataset is documented. Teams can track where it came from and how it was labeled.
- Diversity and coverage: The dataset includes examples from different scenarios, cases, and edge conditions. This helps the AI handle a wide range of situations.
- Continuous review: Gold standard sets are updated regularly. As new data or challenges arise, the dataset evolves to stay relevant.
For example, a medical AI company worked with iMerit to build a gold standard evaluation set for clinical report generation. The project used expert-reviewed medical images and detailed clinical notes. Domain specialists validated the annotations and ensured that each sample met clinical and regulatory expectations.
This expert-led process helped the company create evaluation sets that supported safe model tuning, improved diagnostic accuracy, and aligned with compliance requirements.
Building and Maintaining Gold Standard Evaluation Sets
Creating and sustaining gold standard evaluation sets requires a structured approach. Enterprises can follow these steps:
- Define key use cases and metrics
Determine which AI applications are essential and which metrics are most important first. To make sure
assessment sets focus on the appropriate goals, concentrate on high-risk or business impact scenarios. - Engage cross-functional teams
Teams should then involve both technical and domain experts. Data scientists bring modeling insight,
while subject-matter experts verify labels and context. - Implement clear labeling protocols and audit trails
Establish standardized procedures for labeling data. Track every change and annotation to support
reproducibility, accountability, and audits. - Use Human-in-the-Loop and synthetic data when needed
Human-in-the-loop (HITL) review improves quality and helps to catch edge cases. Synthetic data can
supplement rare scenarios and expand coverage without compromising reliability.
A practical example is reinforcement learning from human feedback, also known as RLHF. During RLHF
phases, gold standard evaluation sets are used to rank model outputs and guide improvements.
iMerit worked with a leading AI company to perform conversation ranking tasks to make sure the model
behaves as expected in real-world contexts. This shows how carefully curated datasets can directly
improve model performance and safety.
Additionally, the technique is more effective with the appropriate tools and expertise. iMerit helps
businesses create and manage evaluation sets at scale by combining qualified reviewers, proficient human
annotators, and sophisticated data pipelines. This method gives organisations trust in their AI systems by
ensuring that AI models are validated on precise and high-quality data.
Measuring the ROI of Gold Standard Evaluation
Investing in gold standard evaluation sets can seem expensive at first. But the benefits usually outweigh
the cost. Reliable evaluation improves performance and builds trust. Yet, many companies struggle to
measure this value because benefits appear across teams and workflow stages. That is why it’s important to
track ROI in a clear and organized way.
Here is the simple framework enterprises can use to estimate ROI:
- Define baseline metrics: Measure current issues caused by weak evaluation. These include errors, rework, model retraining, or
delays in deployment. - Track improvements: Compare the same metrics again after implementing a gold standard evaluation set. Look for faster cycles
and more stable performance. - Translate gains into value: Convert improvements into cost savings or business benefits. For example:
- Less rework saves time and money.
- Faster deployment accelerates time-to-market.
- Reduced compliance issues lowers risk.
- Consider qualitative benefits: Not all benefits show up as numbers. Strong evaluation builds trust with stakeholders and improves audit
readiness. It also supports a stronger and more reliable brand reputation. - Compare investment vs. gains: Finally, weigh the cost of building and maintaining evaluation sets against the measurable and qualitative
benefits. This shows the real business value of reliable evaluation.
This framework can help companies clearly see how high-quality evaluation supports efficiency and overall
enterprise success.
Automation Meets Oversight: Maintaining the Gold Standard
Maintaining gold standard evaluation sets needs balancing automation with expert oversight.
- AI-assisted annotation: AI annotations help to speed up the labeling process so the teams can handle large datasets faster. It
also flags possible errors. - Expert validation: Human reviewers and domain experts check the labels for accuracy and to catch issues that automated tools
may miss. - Continuous evaluation: Regular monitoring can keep the model performance and datasets up to date. It also makes sure the benchmark
stays accurate as data and business needs change.
iMerit’s annotation platform (Ango Hub) combines machine-learning-assisted automation with expert human
validation. This hybrid approach enables evaluation datasets to scale and evolve efficiently, while
preserving high accuracy and domain coverage. Enterprises can detect model drift and maintain AI evaluation
robustness to improve their AI reliability through continuous review without sacrificing precision.
Conclusion
Gold standard evaluation sets are the backbone of reliable AI evaluation in enterprises. They help AI
models perform precisely and safely across real-world scenarios. Enterprises that invest in gold standard
evaluation sets gain measurable value and confidence in their AI systems. It also supports their long-term
success and responsible AI adoption.
Key Takeaways
- Gold standard evaluation sets give accurate and expertly checked benchmarks for AI.
- They help teams spot bias and meet compliance needs.
- These evaluation sets support the full AI lifecycle management from training to ongoing monitoring.
- Stronger evaluation improves deployment speed and model confidence across teams.
- Regular updates and human reviews can help to keep the dataset accurate and relevant.
Whether you are building AI for healthcare, finance, customer service, or autonomous systems,
iMerit scholars help you reach enterprise-grade reliability. Their team can make sure that your AI
performs well in real-world conditions.
Partner with us today!




















