
The next frontier of artificial intelligence is not a screen. It is a kitchen counter, a warehouse floor, and a hospital corridor. AI systems are increasingly expected to move through the physical world, perceive it in real time, and act within it with precision. That shift from digital intelligence to embodied intelligence is one of the most demanding transitions the industry has ever attempted, and the data challenge at its center is unlike anything that came before.
At the heart of that challenge is perspective. Traditional computer vision datasets capture the world from fixed cameras or third-person viewpoints. But a robot learning to fold laundry, prepare a meal, or sort objects on a shelf does not see the world that way. It sees what its own sensors see, from its own vantage point, as it moves through a task. That is precisely why egocentric video data collection has emerged as the essential catalyst for this transition.
Without first-person video datasets that reflect how agents actually experience the world, the models we build to power physical AI will always be learning from the wrong angle.
Why Training Robotic Foundation Models Is So Hard
Building robotic foundation models capable of generalizing across physical environments is not simply a matter of gathering more data. The nature of the data matters enormously, and capturing it at scale introduces challenges that sit at the intersection of logistics, diversity, and quality.

Physical environments are messy and variable in ways that studio recordings never capture. The way natural light shifts across a kitchen in the morning versus the afternoon changes how surfaces, shadows, and objects appear on camera. Clutter, layout variations, and the subtle differences between how one person loads a dishwasher versus another all represent meaningful signals for a model that needs to generalize.
Participant diversity compounds this further. A dataset drawn from a narrow demographic or a single geography will train a model that struggles when it encounters anything outside that narrow slice of the world. Authentic task performance across age groups, body types, handedness, and cultural backgrounds is not a nice-to-have; it is a prerequisite for robust human activity understanding.
And then there is the problem of scale. The volume of footage required to train models capable of handling the long tail of real-world variation is substantial. Curating that footage manually, frame by frame, is not something most organizations can sustain without a structured, enterprise-grade operation behind it.
Core Capabilities in Egocentric Video Data Collection
Addressing these challenges requires more than a camera and a willing participant. A mature egocentric video data collection program is built on three interlocking capabilities.
Wearable Technology for Authentic Capture
The hardware used to record first-person video matters as much as the environments being recorded. Head-mounted cameras, wrist-worn sensors, and eye-tracking devices each offer a different window into how a person experiences a task. The choice of device shapes the field of view, the frame rate, and the fidelity of motion representation, all of which downstream models will need to process accurately.
Calibrating wearable recording setups for consistency across participants is essential, as it ensures that footage collected from one person in one location is compatible with footage from another. That consistency at the point of capture reduces noise in training data and simplifies the annotation pipeline that follows.
Activity-Specific Scenario Design
The scenarios selected for recording are not arbitrary. A model trained to assist in domestic environments needs footage of granular tasks: the way a hand moves when transferring a pan from a stovetop to a counter, the sequence of motions involved in sorting laundry by color, the reach-and-grasp patterns that vary when clearing a cluttered table. Generic activity capture cannot provide this level of specificity.
Recording protocols built around taxonomies of tasks distinguish between action types and sub-actions with enough precision that the resulting data can train models to recognize not just that a person is cooking, but which phase of a recipe they are in and how their hands are positioned at each step.
Human-in-the-Loop Quality at Scale
Technology alone does not produce high-quality training data. A managed global workforce brings the contextual judgment that automated systems cannot replicate: recognizing when a recording is unusable due to motion blur, flagging when a participant has deviated from the scenario protocol, and ensuring that annotation work reflects a genuine understanding of the activity being labeled.
This human-in-the-loop model is what allows egocentric video data collection programs to scale without sacrificing the quality that model training depends on.
From Raw Footage to AI-Ready Data: The Role of Annotation
Capturing footage is only the first step. Transforming raw video into structured, model-ready data requires an annotation process designed for the specific demands of embodied AI.
Ango Hub, iMerit’s enterprise-grade annotation and workflow automation platforms, brings together the tooling, automation, and quality infrastructure needed to handle video data at scale. For pose estimation and movement tracking, the Skeleton tool in Ango Hub enables keypoint-based annotation across frames, allowing annotators to label and connect points such as human joints to form structured skeletons. This supports precise modeling of posture, movement, and the relationships between body points, which is essential for training humanoid and robotic arm systems. Beyond keypoint annotation, Ango Hub supports bounding boxes, polygon annotation, semantic segmentation, and object tracking, giving teams a unified environment for multi-modal labeling within a single workflow.
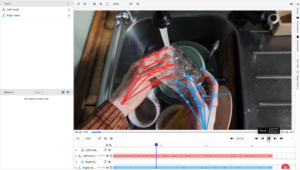
The platform also incorporates automation features that reduce manual effort on repetitive labeling tasks, freeing annotators to focus on complex edge cases that require genuine judgment. Analytics and real-time visibility into annotation performance allow project teams to identify bottlenecks early and maintain output quality as programs scale. From a security standpoint, Ango Hub operates under ISO 27001:2013 certification, SOC 2 compliance, GDPR certification, and HIPAA compliance, with the ability to deploy in region-specific instances to meet data residency requirements.
Human activity understanding is a layered problem. A single clip of someone washing dishes involves object detection, action classification, temporal sequencing, and spatial reasoning about how hands relate to tools and surfaces. Annotation frameworks must capture all of these dimensions simultaneously, and annotators must be trained to apply them consistently. Multi-stage quality assurance closes the loop, with structured review cycles checking annotation consistency, frame coverage, and alignment with the original task taxonomy.
Real-World Application: Training Next-Gen Humanoids
One of iMerit’s recent programs illustrates what this looks like in practice. A robotics startup developing next-generation humanoid systems needed to train their models on 200 hours of real-world task performance across a range of domestic scenarios.
Read the case studies here:
iMerit coordinated the recording operation, managed participant recruitment, and delivered annotated footage organized around a taxonomy of 9 task types and 37 sub-classifications. That level of granularity meant the client’s model could learn not just to recognize “kitchen activity” as a broad category, but to distinguish between the motion signatures of chopping versus stirring, of opening a cabinet versus closing a drawer.
The specificity of that taxonomy was not incidental. It was the result of close collaboration between iMerit’s data operations team and the client’s model architects, who understood which distinctions their system needed to internalize before it could perform reliably in real environments.
Conclusion
Embodied AI is only as capable as the data that trains it. First-person video datasets built with intentional scenario design, diverse participant representation, and rigorous annotation are the foundation on which the next generation of physical AI systems will be built.
iMerit has the infrastructure, the managed workforce, and the annotation tooling to help organizations scale egocentric video data collection programs with the quality and consistency that enterprise model training demands.
If you are building robotic systems that need to understand and act in the physical world, we would welcome the opportunity to discuss how iMerit can support your data program.
























