
McKinsey reports that only one-third of companies have scaled AI beyond pilot deployments, with the gap even wider for AI agents. While pilots are common, production adoption remains limited.
A major barrier is reliability in real environments. As agents take on autonomous tasks, traditional offline benchmarks and static accuracy metrics fail to capture how they behave in production. These metrics do not reflect whether agents complete workflows end-to-end, use tools correctly, or escalate appropriately when uncertainty arises. In live systems, these gaps lead to agent failures that increase operational costs, introduce downstream errors, and create compliance risk.
Building production-ready agentic systems requires a shift in agent evaluation in production toward behavior-driven metrics. Rather than relying only on offline benchmarks, this blog explores how teams can evaluate AI agents in production using task success, tool-use correctness, and escalation quality to ensure reliability and scalability at deployment.
Rethinking Evaluation for Production AI Agents
As AI agents move from pilots to live systems, agent evaluation in production must change. Production agents often operate across multi-step workflows such as ticket resolution, data validation, or system orchestration. These workflows require agents to maintain state, forward intermediate outputs, and make decisions that depend on earlier actions.
Failures often occur when agents select incorrect tools, mishandle intermediate results, or propagate small errors from step to step. Inputs can also change mid-task due to evolving user intent, delayed API responses, or inconsistent behavior from external systems. Static tests cannot capture this behavior, as agents must adapt dynamically to changing contexts in real time.
Traditional evaluation was built for single-turn predictions. Metrics such as accuracy and benchmark scores assume fixed inputs and isolated outputs, breaking AI agents in production. Early decisions affect later steps, and small errors often compound into larger failures; offline evaluation does not show how agents reason, recover, or degrade over time.
In live systems, agents face noisy user intent, unreliable tools, latency, and human handoffs. Measuring task success and tool-use correctness under these conditions is essential. Sequence-level evaluation shows how behavior unfolds across full workflows rather than in individual responses. Human-in-the-loop review adds another layer by catching subtle errors that automated metrics miss.
Focusing on end-to-end behavior allows agent evaluation in production to reflect real performance. Teams gain clearer signals for improving models, refining workflows, and monitoring reliability at scale. This closes the gap between controlled testing and real-world deployment.
Evaluating Task Success in Production
Building on behavior-based evaluation, task success in production must be measured across full workflows, not isolated steps. This approach reflects how agents actually operate in live systems, where success depends on completing tasks under real-world constraints. Proper evaluation captures not only completion but also accuracy, consistency, compliance, and downstream effects.
- Workflow definition: Clear start and end conditions for each task enable consistent and repeatable evaluation.
- End-to-end task success: Measures whether workflows complete with intended outcomes, reflecting true agent performance beyond individual steps.
- Partial completion points: Identifies where failures occur in multi-step workflows, helping teams target specific breakdowns.
- Time to completion: Tracks how long full workflows take to execute, highlighting efficiency and latency issues.
- Retry and correction frequency: Shows how often agents repeat or fix actions, signaling instability or reasoning errors.
- Output quality: Evaluates the accuracy and relevance of final results to prevent downstream errors and rework.
- Policy and constraint adherence: Ensures compliance with rules and regulations, reducing operational and compliance risk.
- Consistency across tasks: Assesses stability of outcomes for similar workflows, building trust in production AI systems.
- Downstream impact: Captures effects on dependent systems and processes, highlighting compounding operational risk.
By evaluating these dimensions, organizations can quantify workflow-level task success, generate actionable insights for model improvement, and refine workflows for scalable deployment. Combined with tool-use correctness and escalation quality metrics, this provides a comprehensive framework for reliable AI agent evaluation in production. Structured evaluation, supported by human-in-the-loop oversight, further ensures that nuanced errors are detected and mitigated.
Evaluating Tool-Use Correctness
Agents rely on APIs, internal software, and external systems to gather data, process information, or execute actions. Evaluating tool-use correctness ensures agents select appropriate tools, execute them accurately, and handle failures safely (critical for reliability, operational trust, and workflow efficiency).
Rather than treating tool use as a single behavior, evaluation must account for both the quality of decisions and the quality of execution. Misusing tools, unnecessary invocations, or mishandling outputs can introduce errors that cascade across workflows. This makes trace-level analysis essential for detecting incorrect sequencing, skipped steps, or recurring misuse, supporting workflow refinement and retraining.
- Tool selection accuracy: Evaluates whether the agent chooses the correct tool based on task context, preventing logic errors and inefficiencies.
- Tool invocation patterns: Analyzes frequency and necessity of tool calls to identify redundant usage or reasoning gaps.
- Execution correctness: Assesses accuracy of parameters, arguments, and input formatting to reduce workflow failures.
- Error handling and recovery: Measures how agents respond to tool failures or incomplete responses, limiting cascading errors.
- Multi-step sequencing: Examines order and dependency management across tool calls to ensure correctness in complex workflows.
- Output validation: Checks whether tool responses are verified before downstream use, preventing propagation of inaccurate data.
- Failure pattern trends: Tracks recurring misuse or breakdowns over time, supporting targeted retraining and workflow refinement.
Evaluating these dimensions together provides a practical view of tool-use correctness in production AI systems. By analyzing selection logic, execution behavior, and sequence-level interactions, organizations can reduce operational risk and improve efficiency. This helps ensure that agents use tools consistently, predictably, and safely at production scale.
Evaluating Escalation Quality
When agents encounter uncertainty, errors, or tasks beyond their capabilities, timely escalation to humans or specialized systems prevents workflow failures and reduces risk. Evaluating escalation quality ensures agents escalate appropriately, provide sufficient context, and balance operational load effectively.
Effective escalation supports risk management, maintains user confidence, and allows production AI systems to operate safely at scale. It can be policy-driven, triggered by workflow rules, or uncertainty-driven, prompted by ambiguous inputs or low confidence. Choosing the correct escalation type (human vs. specialized system) ensures tasks are routed efficiently and reliably.
- Escalation triggers: Assesses conditions prompting escalation, such as uncertainty, policy constraints, or task complexity, ensuring interventions occur only when necessary.
- Escalation type: Evaluates whether escalation is directed to humans or specialized systems, matching tasks with appropriate expertise.
- Timing in the workflow: Measures when escalation occurs during the task lifecycle, ensuring it is early enough to prevent errors but not premature.
- Context quality: Reviews completeness and clarity of information provided during escalation to enable rapid and accurate resolution.
- Escalation frequency: Tracks appropriate, false, and missed escalations to balance trust, workload, and operational efficiency.
- Recurring failure patterns: Identifies trends in improper or delayed escalation, informing workflow redesign, policy updates, or model retraining.
By systematically evaluating these dimensions, organizations can ensure that AI agents escalate safely and efficiently, supporting both operational reliability and user confidence. Combined with metrics for task success and tool-use correctness, escalation evaluation completes the core framework for production-ready AI agent performance.
These three evaluation areas together form the foundation of behavior-based agent evaluation in production. These metrics provide a structured way to assess agent behavior beyond static benchmarks. The table below summarizes how each evaluation area contributes to reliable, scalable production AI systems and sets the stage for understanding why human oversight remains essential.
| Evaluation Area | What It Captures at a High Level | Value for Production AI Agents |
| Task Success | Whether agents reliably complete real-world workflows end-to-end under live conditions | Confirms agents deliver intended business outcomes and remain dependable at scale |
| Tool-Use Correctness | How effectively agents interact with tools, systems, and APIs during execution | Reduces operational errors, inefficiencies, and cascading failures in workflows |
| Escalation Quality | How well agents recognize limits and involve humans or systems when needed | Ensures safety, trust, and continuity when automation encounters uncertainty |
Human-in-the-Loop Evaluation
Even with metrics for task success, tool-use correctness, and escalation quality, AI agents require human oversight to catch complex or contextual errors. Human-in-the-loop evaluation involves reviewing agent traces, interpreting ambiguous outputs, and identifying context-specific failures.
This oversight becomes critical when agents operate across evolving inputs, partial context, or loosely defined objectives. Human reviewers assess whether agent decisions align with business intent, policy constraints, and expected reasoning paths, not just final outputs. Their feedback feeds directly into retraining, prompt refinement, and tool-use correction, helping production agents remain reliable as workflows scale and change.
Human-Led Annotation and Quality Control
Structured human annotation ensures outputs are evaluated consistently against task requirements, business rules, and compliance standards. Reviewers follow clear guidelines, perform inter-annotator checks to maintain consistency, and flag discrepancies for clarification.
Feedback loops capture recurring errors, workflow gaps, or misaligned metrics, feeding directly into model retraining, prompt tuning, and workflow refinement. Integrating these processes keeps AI agents in production aligned with evaluation standards and reduces repeated errors over time.
Operationalizing Agent Evaluation
Scaling agent evaluation in production requires structured pipelines that continuously capture interactions, track performance, and generate actionable insights. Operationalizing the evaluation ensures it is not a one-off activity but a systematic, repeatable process embedded into workflows. This allows teams to monitor performance across multiple agents, detect failures early, and maintain operational reliability, while producing data that informs both technical improvements and business decisions.
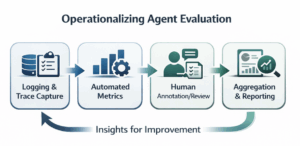
Building Scalable Evaluation Pipelines
Effective pipelines begin with logging and trace capture, recording every agent action, tool call, and decision. This gives teams clear visibility into sequential behavior, decision logic, and error propagation, helping them see not only what agents do but also how they navigate multi-step workflows and make decisions across tasks.
Human oversight, including structured annotation and review, complements automated metrics. Using iMerit’s human-in-the-loop evaluation, reviewers follow clear guidelines and consistency checks to catch nuanced errors, interpret ambiguous outputs, and identify context-specific issues that automated systems might miss.
Metric aggregation and reporting allow teams to track trends in task success, tool-use correctness, and escalation quality, uncover recurring failure patterns, and spot workflow bottlenecks. Governance policies around data management, annotation, and metric definitions ensure consistency, compliance, and repeatability across agents and teams. Together, these components create a robust framework for ongoing evaluation and improvement of AI agents in production.
Closing the Loop Between Evaluation and Improvement
Evaluation is only impactful if insights drive continuous improvement. By analyzing patterns in task performance, tool usage, and escalation behavior, organizations can identify recurring errors, optimize workflows, and refine agent models. Continuous monitoring ensures agents remain reliable, adaptive, and aligned with changing inputs, policies, and operational expectations.
Integrating iMerit’s human-led annotation and quality control processes further strengthens evaluation, capturing subtle errors and operational edge cases that automated metrics alone may miss. This combination of structured data, metrics, and human insight ensures AI agents perform safely, consistently, and efficiently at scale.
Conclusion
Agent evaluation in production requires focusing on task success, tool-use correctness, and escalation quality rather than static benchmarks. Structured human-in-the-loop evaluation captures nuanced errors and supports workflow improvement. Embedding these practices into scalable pipelines ensures reliability, reduces operational risk, and drives measurable business outcomes.
To implement these strategies effectively, reach out to iMerit for expert guidance on deploying AI agents safely and efficiently at scale.
























