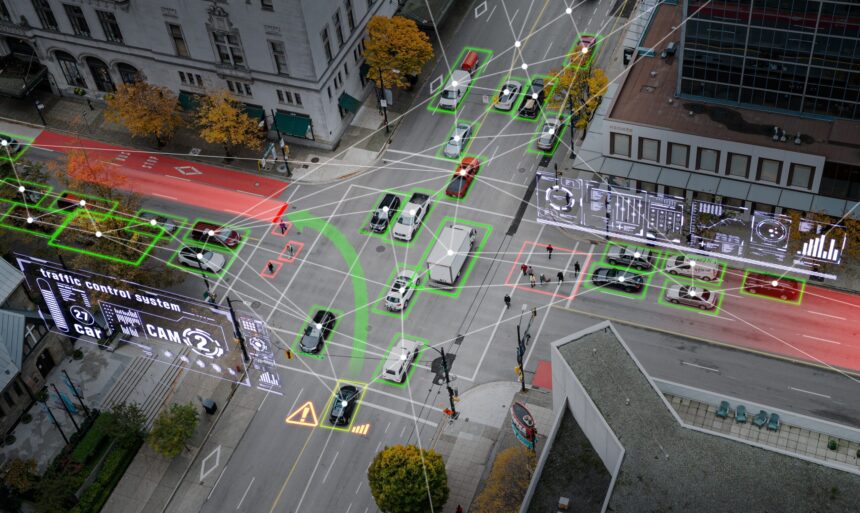
The success of machine learning models hinges on the quality of data they’re trained with. Behind every breakthrough in computer vision, natural language processing, or autonomous systems lies countless hours of meticulous data preparation. Two terms frequently used in this domain—data annotation and data labeling—often cause confusion even among seasoned AI practitioners. Though seemingly interchangeable, these processes represent distinct approaches to preparing training datasets, each with unique methodologies, tools, and applications.
What is Data Annotation?
Data annotation is the process of adding informative metadata to raw datasets, creating the structured foundation machine learning models need to learn effectively. This process transforms unstructured data into meaningful training material by embedding human expertise directly into the dataset. Annotation spans multiple formats: images (using bounding boxes and segmentation), text (marking entities and relationships), video (tracking objects across frames), and audio (identifying speakers and sounds). These enhanced datasets provide the ground truth signals that enable AI systems to recognize patterns, make accurate predictions, and develop sophisticated capabilities across various applications.
Data Annotation Use Cases
Computer Vision Enhancement
In advanced computer vision applications, annotation involves creating precise polygon boundaries around objects, defining semantic segmentation masks, establishing relationships between objects, and tracking movement across video frames. These detailed annotations enable models to understand complex visual scenes with a nuanced understanding of spatial contexts.
Medical Imaging Analysis
Medical professionals annotate radiological images by marking specific pathologies, measuring dimensions of anatomical structures, and providing diagnostic commentary. These annotations incorporate specialized medical knowledge and terminology that help AI systems learn to identify subtle indicators of disease.
Natural Language Understanding
Linguistic experts annotate text with syntactic structures, semantic roles, coreference relationships, and pragmatic features. This detailed linguistic markup helps models understand language at a deeper level, capturing meaning beyond surface-level patterns.
Autonomous Vehicle Training
Engineers annotate sensor data with detailed road conditions, traffic sign specifications, pedestrian intentions, and environmental factors. These annotations incorporate real-world driving knowledge and help vehicles understand complex traffic scenarios.
What is Data Labeling?
Data labeling is a more straightforward classification process that assigns predefined categories or tags to data points. It typically involves placing items into discrete classes or attaching simple identifiers to data elements. Labeling focuses on sorting data into established taxonomies rather than adding rich contextual information. This process is often more standardized and can be performed by individuals with less specialized knowledge, making it suitable for distributed workforce models and higher volumes of data processing.
Data Labeling Use Cases
Image Classification
Labelers assign predefined categories to images, such as “dog,” “cat,” or “vehicle,” creating the foundation for basic recognition systems. This straightforward classification enables models to differentiate between distinct visual categories.
Sentiment Analysis
Content moderators label text as “positive,” “negative,” or “neutral” to train sentiment analysis models. These simple categorizations help systems understand the emotional tone of written content.
Content Moderation
Platform reviewers label content as “appropriate” or “inappropriate” based on community guidelines. These binary or simple multi-class labels help automated systems filter potentially problematic content.
Voice Command Recognition
Audio labelers mark recordings as specific commands or requests, enabling voice assistants to recognize standardized instructions. These labels help systems match audio patterns to expected actions.
Key Differences Between Data Annotation vs Labeling
Complexity and Depth
Annotation involves detailed markup with rich contextual information that captures nuances and relationships within the data. Labeling, meanwhile, focuses on simpler classification into predefined categories without extensive contextual details.
Required Expertise
Annotation typically requires domain expertise and specialized knowledge to properly contextualize data within its field. Labeling can often be performed by generalists with basic training in following category guidelines.
Time and Resource Investment
Annotation demands greater time investment per data point but produces richer training data that can enable more sophisticated model behaviors. Labeling processes are generally faster but produce more basic training signals.
Resulting Model Capabilities
Models trained on annotated data demonstrate more nuanced understanding and can perform complex reasoning within their domains. Those trained on labeled data excel at classification tasks but may lack deeper contextual understanding.
Choosing Between Data Annotation vs Data Labeling
The decision between annotation and labeling isn’t simply a technical choice—it’s a strategic investment in your AI’s future capabilities. Your selection should align with project complexity, desired model sophistication, and available expertise. For teams navigating this critical decision, iMerit’s Ango Hub offers a unified AI data workflow automation platform that excels at supporting both approaches.
Ango Hub’s AI-Assisted features automate AI data workflows to improve labeling efficiency and model reinforcement learning from human feedback (RLHF), allowing domain experts to focus on providing high-quality data rather than repetitive tasks. Our platform is built on quality-first principles to deliver precise annotations for training sophisticated AI models across diverse applications. Whether your project requires simple classification or detailed contextual markup, Ango Hub supports image and video annotation, text, document, and audio annotation with intuitive keyboard shortcuts that make it easy for annotators of all skill levels to work with multiple data types of any size. Contact our experts today to discover how Ango Hub can accelerate your AI development journey!
References:
https://imerit.net/products/ango-workflow-automation-by-imerit/
https://imerit.net/solutions/computer-vision/data-annotation-services/
https://imerit.net/solutions/computer-vision/image-annotation-services/
https://imerit.net/solutions/natural-language-processing/text-annotation-services/
https://imerit.net/solutions/computer-vision/video-annotation-services/
https://imerit.net/solutions/natural-language-processing/audio-transcription/
https://imerit.net/solutions/computer-vision/
https://imerit.net/domains/medical-ai/data-annotation-for-digital-radiology/
https://imerit.net/solutions/natural-language-processing/
https://imerit.net/domains/autonomous-vehicles/
https://imerit.net/blog/what-is-data-annotation/
https://imerit.net/contact-us/





















