
Autonomous systems across sectors often work without human intervention. Self-driving vehicles navigate busy highways. Agricultural robots and precision sprayers manage crops, and delivery and surveying drones map terrain.
Despite their differences, these systems share one requirement: an accurate understanding of object boundaries. An autonomous machine must know where an object begins and ends. Since a misidentified edge can cause an incorrect classification, leading to unsafe action.
3D semantic segmentation helps machines perceive edges and occluded objects (boundary detection) by leveraging rich sensor data (LiDAR, cameras, radar).
In this article, we will learn the role of 3D semantic segmentation across autonomous domains and why high-quality data annotation is the foundation of reliable autonomous perception.
Why Object Boundary Accuracy Is a Safety-Critical Problem
Autonomous systems depend on accurate boundary detection to operate safely in real-world environments. An error at the edge of an object can propagate and lead to unsafe decisions.
The impact appears across many autonomous domains:
- Autonomous Vehicles (AVs): A vehicle misreading the edge of a pedestrian near a concrete pole may calculate an unsafe path, causing a collision or braking.
- Agricultural Robots: A robot that cannot distinguish the boundary between a plant canopy and soil may damage crops
- Industrial Arms: A warehouse robot arm misjudging a pallet boundary may drop a heavy payload or collide with surrounding infrastructure.
- Drones: A surveying drone flying through a dense tree canopy may lose altitude and hit branches.
Traditional 2D camera-based perception struggles because images lack depth. It can show appearance, but cannot reliably determine distance or true physical boundaries.
Reliable boundary detection requires spatial awareness, enabled by 3D perception data.
What Is 3D Semantic Segmentation and How Does It Differ from 2D?
3D semantic segmentation is the process of assigning a semantic class label to every point in a 3D point cloud, such as pedestrian, vehicle, road surface, tree, or obstacle.
A point cloud is a dataset of millions of 3D coordinates. When every point has a label, a system can understand where an object is in three dimensions, what shape it has, and where its edges meet the surrounding environment.
2D segmentation operates on pixels in a flat image. It can outline objects but lacks depth information. It cannot distinguish real gaps from overlapping objects.
In contrast, 3D segmentation encodes spatial coordinates, so the system reasons about depth, separation, and occlusion without inference.

Here is a difference table:
| Feature Category | 2D Semantic Segmentation (Cameras) | 3D Semantic Segmentation (Point Clouds) |
| Data Structure | A regular grid of pixels defined by (U, V) coordinates. | An unstructured, continuous collection of distinct points defined by absolute (X, Y, Z) spatial coordinates. |
| Depth Perception and Scale | Depth is inferred indirectly; prone to scale ambiguity and perspective errors. | Depth and scale are absolute, physically measured metrics that cannot be distorted by visual perspective. |
| Lighting Dependency | Dependent on ambient light, performance degrades greatly in glare, shadows, or darkness | Largely independent of ambient light, as active sensors generate their own measurement signals. |
| Boundary Clarity and Occlusion | Edges blur due to shadows, poor contrast, or 2D overlap between visually similar objects | Edges are defined by measurable spatial discontinuities and absolute distance between surfaces. |
The Boundary Problem in 3D Point Clouds
Despite the advantages of 3D data, modeling point cloud segmentation boundaries is more difficult than interiors. The center of a vehicle, the middle of a concrete wall, or the trunk of a tree consists of dense, uniform points that share the same semantic class and consistent geometry. But the boundaries are irregular transition zones where abrupt geometric shifts and sensor limitations create modeling challenges.
Several technical factors cause this:
- Point sparsity at edges: Laser pulses may miss edges, or thin structures like wires or branches might then be represented by only a few points.
- Sensor noise and reflectivity: Lasers striking reflective or curved surfaces return scattered signals that create noise halos around boundaries, making it harder to distinguish object edges.
- Dynamic occlusion: As the system moves, foreground edges constantly cover and uncover background objects, creating fluctuating point densities that confuse models tracking a stable border over time.
- Range image projection distortion: When 3D point clouds are flattened into 2D range images for faster processing, distant background points and near-foreground boundary points fall into adjacent pixels. Standard convolution blurs them together and destroys the sharp boundary transition.
How 3D Segmentation Encodes Boundary Accuracy
3D semantic segmentation captures object boundaries by assigning a label to every point in a point cloud, allowing the model to trace object contours.
That point-level labeling lets the system preserve fine structural details such as thin poles, tree branches, or curb edges. As a result, boundaries are defined by the geometry of the scene rather than by coarse shapes.
To identify where one object ends and another begins, the algorithm relies on local geometric features. It analyzes the surface normals, curvature, and depth changes.
When the algorithm detects sudden changes in these properties, it signals that a physical boundary is present. Many point cloud processing pipelines estimate these features by fitting local planes to neighboring points and analyzing their orientation differences, which helps detect edges even in noisy or complex environments
Different representation strategies handle these boundary features in different ways:
- Point-based representations process raw data directly, preserving spatial detail for accurate edge detection.
- Voxel-based methods divide space into 3D grids, improving efficiency but potentially smoothing fine boundaries.
- Graph-based representations connect neighboring points, helping track continuous surfaces and define object borders.
When boundaries are encoded accurately, they improve downstream tasks such as collision avoidance, object manipulation, and path planning by enabling more precise decisions.
Advanced Techniques for Sharpening Fuzzy Edges
Standard neural networks apply equal weight to all points, including complex boundary zones. Several techniques address this:
- Boundary-aware attention networks: Identify transition zones and direct more computational focus toward edge regions, reducing misclassification at object borders.
- Edge-vertex fusion: Combines point-level features with the geometric relationships between neighboring points, extracting richer boundary structure.
- Multi-scale feature extraction: Analyzes the point cloud at multiple resolutions in parallel, deep layers capture macro-structure and global context, shallow layers capture fine edge detail. Fusing both scales keeps boundaries sharp without sacrificing semantic accuracy.
No single sensor handles boundaries perfectly in all conditions, which is where fusion-based techniques come in:
- Sensor fusion: LiDAR provides depth but lacks color and texture. RGB cameras define clear visual edges but fail at depth estimation and in low light. Radar performs well in bad weather but at a lower resolution. Combining sensors improves boundary detection; a color contrast detected by a camera can sharpen an ambiguous boundary in the LiDAR point cloud.
- Range-aware convolution: When 3D point clouds are projected onto 2D range images, standard convolution treats neighboring pixels as physically close even when one is a nearby car edge, and the next is a wall 50 meters away. Range-aware methods weight contributions by actual 3D distance rather than 2D pixel proximity, preventing background surfaces from blending into foreground edges.
Role of High-Quality Data Annotation and Ground Truth in Boundary Accuracy
Boundary accuracy depends heavily on high-quality data annotation services, yet 3D point cloud annotation presents unique challenges. Annotators face challenges like occlusions, scale variation, and domain shift.
Solving this requires multi-stage Quality Assurance (QA) workflows and strict inter-annotator consistency. Organizations must develop domain-specific labeling protocols tailored to the exact type of autonomous system being trained.
While automated labeling tools are useful, human-in-the-loop annotation remains crucial. Automated systems often struggle with the complex structure of boundary points. Skilled human annotators are needed to resolve edge cases and ensure accurate ground truth data.
How iMerit Supports Boundary-Accurate 3D Semantic Segmentation
Achieving boundary accuracy for production-grade autonomous systems requires specialized tooling, trained human expertise, and rigorous, enterprise-grade QA. At iMerit, we provide an end-to-end 3D point cloud annotation solution engineered to deliver high-precision 3D perception datasets across autonomous domains.
We support point-by-point semantic segmentation, 3D cuboids with boundary precision, and instance segmentation. For multi-sensor systems, iMerit labels across LiDAR, depth cameras, RGB cameras, and radar inputs, overlaying camera feeds onto point clouds to ensure boundary consistency across all sensor modalities.
Through Ango Hub, iMerit combines AI auto-labeling with human expertise. Annotators utilize flexible labeling modes, ML snapping, and sensor-aware projections to ensure point cloud boundaries align perfectly with camera imagery.
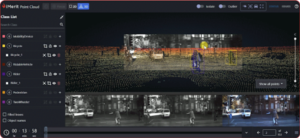
Case Study: LiDAR annotation for a 3D perception system
A leading autonomous vehicle company partnered with iMerit to improve the accuracy of its 3D perception system using LiDAR, cameras, and radar data.
iMerit deployed a trained annotation team to label key objects and refine boundary accuracy across point cloud data.
These high-quality datasets improved scene understanding and enabled more reliable perception models in real-world driving environments.
The Bottom Line
The safe deployment of autonomous systems relies on accurately interpreting object boundaries. 3D semantic segmentation brings point-level detail in autonomous systems that greatly enhances perception and safety. High boundary accuracy results in fewer misclassifications, more dependable planning, and ultimately safer navigation.
If you are looking for 3D Point Cloud Segmentation Annotation Solutions for your autonomous systems, here is how iMerit can help.


















